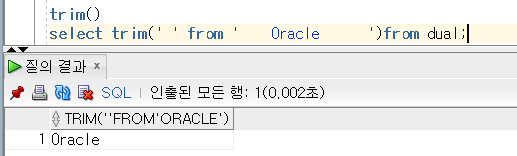
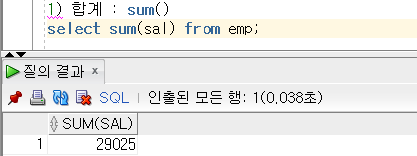
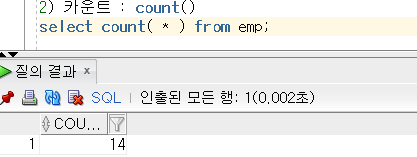
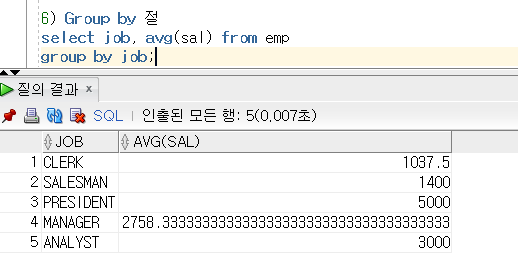
데이터 무결성 제약 조건이란?
DICR (Data Integrity Constraint Rule)
: 테이블에 올바른 데이터만 입력 받고 잘못된 데이터는 들어오지 못하도록 컬럼마다 정하는 규칙을 의미합니다.
| 조건 이름 | 의미 |
| Not null/null | 이 조건이 설정된 컬럼에 null을 허용할 지 아니면 반드시 데이터를 입력받게 합니다. |
| Unique | 이 조건이 설정된 컬럼에는 중복된 값이 입려되지 못하도록 합니다. |
|
Primary key (기본키) |
이 조건은 NOT NULL + UNIQUE의 특징을 가지며 테이블 내에서 데이터들끼리의 유일성을 보장하는 컬럼에 설정합니다. 그리고 테이블당 1개만 설정할 수 있습니다. |
| Check | 이 조건에서 설정된 값만 입력을 허용하고 나머지는 거부합니다. |
| Default | 이 조건이 설정된 커럼에 기본값으로 특정 값이 저장되도록 설정합니다. |
|
Foreign key (외래키) |
이 조건이 다른 테이블의 컬럼을 참조해서 검사를 합니다. |
● 데이터 무결성 제약 조건 확인 하기
desc USER_CONSTRAINTS• owner : 제약 조건을 소유한 사용자명을 저장하는 컬럼입니다.
• constraint_name : 제약 조건명을 저장하는 컬럼입니다.
• constraint_type : 제약 조건 유형을 저장하는 컬럼입니다.
▪ P : primary key.
▪ R : foreign key.
▪ U : unique
▪ C : check, not null
• table_name : 각 제약 조건들이 속한 테이블의 이름입니다.
• search_condition : 어떤 내용이 조건으로 사용되었는지 설명입니다.
• r_constraint_name : 제약 조건이 foreignkey인 경우 어떤 primary key를 참조했는지를 대한 정보를 가집니다.
지금부터 각 조건들의 특징과 사용방법을 예시들을 통해서 설명하겠습니다.
1) Not null : 반드시 데이터를 입력
-- ex) 회사에서 사원을 관리 하기위해서는 이름이나 사원 번호 같은 컬럼에는 null 값이 들어가면 안됩니다.
null 이 들어가게 되면 누구인지 관리가 되지 않기 때문이다.
create table emp02(
empno number(4) not null,
ename varchar2(20) not null,
job varchar2(20),
deptno number(2)
);
사원 번호와 사원 이름 뒤에 not null 넣어서 null 값이 들어오지 못하도록 만듭니다.
insert into emp02 values(null, null, 'saleman', 40 ); -- 사원번호 & 사원이름에 null이 입력 : 오류
insert into emp02 values(null, '홍길동', 'saleman', 40 ); -- 사원번호에 null이 입력 : 오류
insert into emp02 values(1234, null, 'saleman', 40 ); -- 사원이름에 null이 입력 : 오류
2) Unique : 지정된 컬럼에 중복되지 않고 유일한 값만 저장
-- ex) 회사에서 사원을 관리 할 때, 이름과 사원 번호는 꼭 필요하다고 이야기 했습니다. 이름은 동명이인이 존재 할 수
있지만 사원 번호는 절대 중복되면 안됩니다.
create table emp03(
empno number(4) unique,
ename varchar2(20) not null,
job varchar2(20),
deptno number(2)
); 1차적으로 이름은 꼭 필요한 값이기 때문에 not null 을 사용합니다. 다음으로 unique을 사용함으로 사원 번호의 중복을 막습니다.
insert into emp03 values(1234, '홍길동', 'saleman', 40 );
insert into emp03 values(1234, '홍길서','관리부', 40 ); -- 사원 번호 중복 : error
3) constraint : 제약을 지정해주는 명령어 ( 컬럼 레벨로 조건명 명시 )
-- 오류 보고 - ORA-00001: unique constraint (SCOTT.SYS_C007005) violated 에서
-- SCOTT.SYS_C007005 제약 조건명을 직접 입력해줄 수 있다.
create table emp04(
empno number(4) constraint emp04_empmo_uk unique, -- unique 약자 : uk
ename varchar2(20) constraint emp04_ename_nn not null, -- not null 약자 : nn
job varchar2(20),
deptno number(2)
); -- emp04 라는 테이블에 값을 일부러 오류를 내보겠습니다.
insert into emp04 values(1234, '홍길동', 'saleman', 40 );
insert into emp04 values(1234, '홍길서','관리부', 40 ); -- 고의적으로 unique의 오류를 냈습니다.
-- 명명한 것이 오류에 등장합니다. .
-- 오류 보고 - ORA-00001: unique constraint (SCOTT.EMP04_EMPMO_UK) violated
-- 어떤 데이터가 오류인지 조금 더 직관력 있게 확인 할 수 있도록 해줍니다.
4) Primary key(기본키) : not null + unique
-- 사원 번호 같은 경우는 중복만 없으면 안되는 것이 아니라 값은 항상 존재해야 합니다. 그것을 충족해주는 명령어를
사용하겠습니다.
create table emp05(
empno number(4) constraint emp05_empmo_pk primary key, -- primary key 약자: pk
ename varchar2(20) constraint emp05_ename_nn not null,
job varchar2(20),
deptno number(2)
); 사원번호에 primary key를 넣음으로써 항상 값을 취하고 또한 중복되지 않도록 만들었습니다.
nsert into emp05 values(null,'홍길동', 'saleman', 40 );
-- 오류 보고 - ORA-01400: cannot insert NULL into ("SCOTT"."EMP05"."EMPNO")사원번호에 null 입력
insert into emp05 values(1234, '홍길서','관리부', 10 );
-- 삽입OK
insert into emp05 values(1234,'홍길동', 'saleman', 40 );
--오류 보고 - ORA-00001: unique constraint (SCOTT.EMP05_EMPMO_PK) violated 사원번호 중복
5) Foreign key(외래키) : 다른 테이블이 칼럼에 들었있는 값만 저장을 허용
① 부서번호가 기본키인 dept06 이름의 테이블 생성
create table dept06(
deptno number(2) constraint dept06_deptno_pk primary key, -- 부서번호가 기본키
dname varchar2(20),
loc varchar2(20)
);
② dept06 insert into 를 사용하여 내용 삽입
insert into dept06 values(10, '회계부','종로구');
insert into dept06 values(20, '연구서','서대문구');
insert into dept06 values(30, '영업부','영등포구');
③ 부서번호에 외래키를 넣어서 dept06 테이블의 내용의 값을 저장하도록 허용
create table emp06(
empno number(4) constraint emp06_empno_pk primary key, -- primary key 약자: pk
ename varchar2(20) constraint emp06_ename_nn not null,
job varchar2(20),
deptno number(2) constraint emp06_deptno_fk
references dept06(deptno) -- foreign key 약자: fk
);
insert into emp06 values(1234,'홍길동','세일즈맨',30);
insert into emp06 values(1235,'홍길남','점원',40);
-- 오류 보고 - ORA-02291: integrity constraint (SCOTT.EMP06_DEPTNO_FK) violated - parent key not found
-- dept06 안의 데이터에 40이라는 번호가 없기 때문에 오류가 생깁니다. -- 칼럼의 내용에 대한 정보만 들어갈 수 있도록 데이터베이스가 감시줍니다.
그 외의 값이 들어가게 하려면 오류를 낸다.
-- 대상이 바라보는 테이블 (=부모 테이블), 대상을 바라보는 테이블(=자식 테이블)로 정해줍니다.
-- 외래키는 자식에게 걸어주는 것으로, 부모 키가 되기 위한 컬럼은 반드시 부모 테이블의
기본키나 유일키로 설정 되어있어야 합니다.
-- 부모데이블이 unique 의 특성이 필요한 이유는 중복성을 피하기 위함합니다.
6) Check : 저장 가능한 데이터 값의 범위나 조건을 지정하여 설정한 값만 허용
check 문제를 통해서 설명 하겠습니다.
-- 급여 컬럼을 생성하되 값은 500~5000 사이의 값만 저장 가능
-- 성별 저장 컬럼은 gender를 정의하고, 'M'/'F' 둘 중 하나의 값만 저장 가능
create table emp07(
empno number(4) constraint emp07_empno_pk primary key,
ename varchar2(20) constraint emp07_ename_nn not null,
sal number(7,2) constraint emp07_sal_ck check(sal between 500 and 5000),
gender varchar2(1) constraint emp07_gender_ck check(gendr in ('M','F'))
);
-- check 의 약자: ck / 범위= between A and B
-- IN 이라는 키워드를 통해서 OR 의 역할을 할 수 있다. 'M','F' 외의 값이 들어가면 오류가 됩니다.
insert into emp07 values(1234,'홍길동',6000,'M');
-- 오류 보고 - ORA-02290: check constraint (SCOTT.EMP07_SAL_CK) violated / 급여가 5000이상
insert into emp07 values(1235,'홍길남',3000,'m');
-- 오류 보고 - ORA-02290: check constraint (SCOTT.EMP07_GENDER_CK) violated
/ 대소문자를 구분한다는걸 잊지말자!
7) Default : 기본값으로 특정 값이 저장되도록 설정하는 조건
default 문제를 통해서 설명 하겠습니다.
-- 지역명(loc) 컬럼에 아무 값도 입력하지 않을 때, 디폴트 값인 'SEOUL' 이 입력되도록 default 제약 조건 지정.
create table dept08(
deptno number(2) constraint dept08_deptno_pk primary key,
dname varchar2(20) constraint dept08_dname_nn not null,
loc varchar2(20) default 'SEOUL'
);insert into dept08 values(10,'회계부');--테이블에 3개의 값을 넣어야 하는데 2개만 들어가서 : ERROR
insert into dept08(deptno, dname) values(10,'회계부'); -- 결과값 = 10 회계부 SEOUL 로 나타난다. 결과 값이 없어서 NULL 이 들어갈 자리에 SEOUL의 값이 출력되도록 한 것입니다.
8) 제약 조건 명시 방법
① 컴럼 레벨로 조건명 명시해서 제약 조건 설정
- 지금까지 파일명 옆으로 조건을 넣었던 방법입니다.
② 테이블 레벨 방식 제약 조건 설정.
주의) not null 조건은 테이블 레벨 방식으로 제약 조건을 지정할 수 없습니다.
create table emp09(
empno number(4),
ename varchar2(20) constraint emp09_ename_nn not null, -- not null은 무조건 옆으로만 작성이 가능하다.
job varchar2(20),
deptno number(2),
constraint emp09_empno_pk primary key(empno),
constraint emp09_job_uk unique(job),
constraint emp09_deptno_fk foreign key(deptno) references dept06(deptno)
);
-- 컬럼 레벨과 다르게 foreign fey(deptno)를 넣어줘야 한다.
9) 제약 조건 추가하기
alter table emp10 add constraint emp10_empno_pk primary key(empno);
alter table emp10 add constraint emp10_deptno_fk foreign key(deptno) references dept06(deptno);
ALTER을 통해서 수정을 하고 ADD 통해서 추가를 합니다.
10) not null 제약 조건 추가하기
alter table emp10 add constraint emp10_ename_nn not null(ename); -- error
alter table emp10 modify ename constraint emp10_ename_nn not null;
-- 원래 null 이라는 제약 조건이 default 로 되어있기 때문에 add가 아니라 modify 로 사용하면 됩니다.
11) 제약 조건 제거하기
alter table emp10 drop primary key; -- 제거할 때는 drop을 사용
12) 제약 조건(외래키) 컬럼 삭제
delete from dept06 where deptno = 30;
-- 오류 보고 - ORA-02292: integrity constraint (SCOTT.EMP06_DEPTNO_FK) violated - child record found
-- 자식 테이블이 있기 때문에 삭제 되지 않습니다.
-- foreign key 로 연결 되어 있을 때는 삭제 되지 않습니다.( 기준이 되는 테이블이 삭제 되기 때문입니다.) -- 제약 조건의 비활성화
-- 참조 하고 있는 대상(자식)을 다 삭제한후 제약 조건을 삭제합니다.
①
alter table emp06 disable constraint emp06_deptno_fk;
-- DISABLE CONSTRAINT : 제약 조건의 일시 비활성화(자식들을 비활성화)
②
delete from dept06 where deptno = 30;
-- 삭제 완료
③
select * from dept06;
-- 삭제 완료 확인
④
alter table emp06 enable constraint emp06_deptno_fk;
-- 오류 select * from emp06; -- deptno 값이 30이 있기 때문에 활성화 할 수 없습니다.
-- ENABLE CONSTRAINT : 비활성화된 제약 조건을 해제하여 다시 활성화
--1)
insert into dept06 values(30,'총무부','중구'); -- 30번의 부서를 복귀 시킴
--2) 외래키를 가지고 있던 테이블을 찾아서 직접 변경시킵니다.
alter table emp06 enable constraint emp06_deptno_fk; -- 변경 완료
13) Cascade : 부모를 잠깐 비활성화 하면서 자식들까지도 같이 비활성화 해줍니다.
alter table dept06 disable primary key cascade;
-- 부모가 자식까지 영향을 미쳐서 모두 비활성화 된다.
alter table dept06 drop primary key; -- error
alter table dept06 drop primary key cascade;
-- cascade 로 비활성화 시킨거라면 cascade를 넣어서 삭제한다.
alter table dept06 add constraint dept06_deptno_pk primary key(deptno);
-- 삭제를 하고 나서 원래있던 기본키를 넣어준다(원상복귀)'빅데이터 > DataBase' 카테고리의 다른 글
| [DataBase] 서브 쿼리 (Sub - Query)문 (0) | 2020.04.12 |
|---|---|
| [DataBase] 조인(JOIN) (0) | 2020.04.12 |
| [DataBase] 트랜잭션 (Transaction) (0) | 2020.04.12 |
| [DataBase] DML (Data Manipulation Language) (0) | 2020.04.11 |
| [DataBase] DDL (Data Definition Language) (0) | 2020.04.11 |