연속 변수란?
: 시간, 길이 등과 같은 연속성을 가진 실수 단위 변수를 의미합니다.
1) 상자 그래프 시각화 - boxplot()
: 요약정보를 시각화 하는데 효과적. 특히 데이터의 분포 정도와 이상치 발견을 목적으로 하는 경우 유용하게 사용
VADeaths 함수를 활용하여 상자 그래프 에 대해서 알보겠습니다.
< VADeaths >
R에서 기본으로 제공되는 데이터 셋으로 1940 년 미국 버지니아주의 하위계층 사망비율을 기록한 데이터 셋이다 전체
5 행 4 열의 numeric 자료형의 matrix 자료구조를 갖고 있습니다.
변수구성
- Rural Male( 시골출신 남자) Urban Male( 도시출신 남자)
- RuralFemale( 시골출신 여자) Urban Female( 도시출신 여자)
Rural Male Rural Female Urban Male Urban Female
50-54 11.7 8.7 15.4 8.4
55-59 18.1 11.7 24.3 13.6
60-64 26.9 20.3 37.0 19.3
65-69 41.0 30.9 54.6 35.1
70-74 66.0 54.3 71.1 50.0
boxplot(VADeaths, range=0) # 상자그래프 시각화.
abline(h = 37, lty = 3, col="red")점 # abline : 기준선 추가(lty = 3 : 선 (lty : linetype)) range = 0 : 최소값과 최대값 점선으로 연결하는 역할 - 주식에서 많이 사용
최대값과 최소값의 격차를 보여주며, 분포도를 보여줍니다.

2) 히스토그램 시각화
: 탐색과정에서 연속 변수에 관하여 가장 많이 사용합니다.
- 측정값의 범위(구간)를 그래프의 x축으로 놓고, 범위에 속하는 측정값의 빈도수를 y축으로 나타낸 그래프 형태.
iris 함수를 활용하여 히스토그램 에 대해서 알보겠습니다.
< iris >
R에서 제공되는 기본 데이터 셋으로 3 가지 꽃의 종류별로 50 개씩 전체 150개의 관측치로 구성된다. iris는 붓꽃에 관한 데이터를 5 개의 변수로 제공하며각 변수의 내용은 다음과 같다.
Sepal.Length(꽃받침 길이)
Sepal.Width(꽃받침 너비)
Petal.Length(꽃잎 길이)
Petal.Width(꽃잎 너비)
Species(꽃의 종류) : 3 가지 종류별 50 개 (전체 150 개 관측치)
hist(iris$Sepal.Width, xlab = "꽃받침의 너비" , col= "green", xlim = c(2.0,4.5),
main="iris 꽃받침 너비 histogram") xlim : x축의 최소와 최대 범위 표현

의미 : 막대그래프의 2.0~2.25 너비를 가진 것들의 빈도수가 5정도 됩니다.
3) 산점도 시각화
: 두 개 이상의 변수들 사이의 분포를 점으로 표시한 차트를 의미
예제 ①
#기본 산점도 시각화
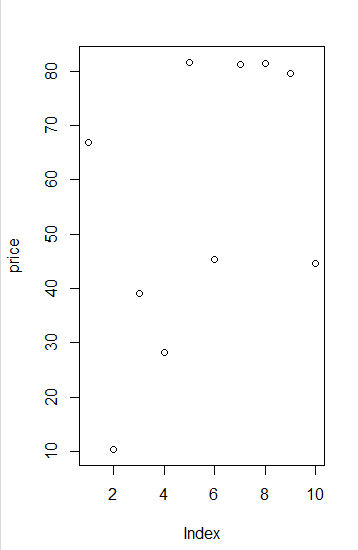
price <- runif(10, min = 1, max = 100) - 1~100 사이 10개 난수 발생
plot(price)runif() : 난수 발생 함수 / runif(생성개수 n개의 랜덤 난수 , 최소 , 최대 ) 최소 ~ 최대 까지에서 n개 난수 생성
예제②
# 대각선 , 텍스트 추가
par(new=T) # 기존 그래프에서 추가적으로 차트을 넣어준다
line_chart <- c(1:100)
line_chart
- 출력값 -
[1] 1 2 3 4 5 6 7 8 9 10 11 12 13 14
15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30
[31] 31 32 33 34 35 36 37 38 39 40 41 42 43 44
45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60
[61] 61 62 63 64 65 66 67 68 69 70 71 72 73 74
75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90
[91] 91 92 93 94 95 96 97 98 99 100
plot(line_chart, type = "l", col = "red", axes = F, ann = F) # 대각선 출력
# 텍스트 추가
text(70,80,"대각선 추가",col = "blue" )
par - plot 안에서 시각화의 개수를 제공해주는 함수
type = "l" : 실선을 넣어줍니다.
axes : 축의 대한 매개변수
ann : T,F의 값을가진다
text(x축,y축,"내용") + col = "색상"
+ 추가 기능
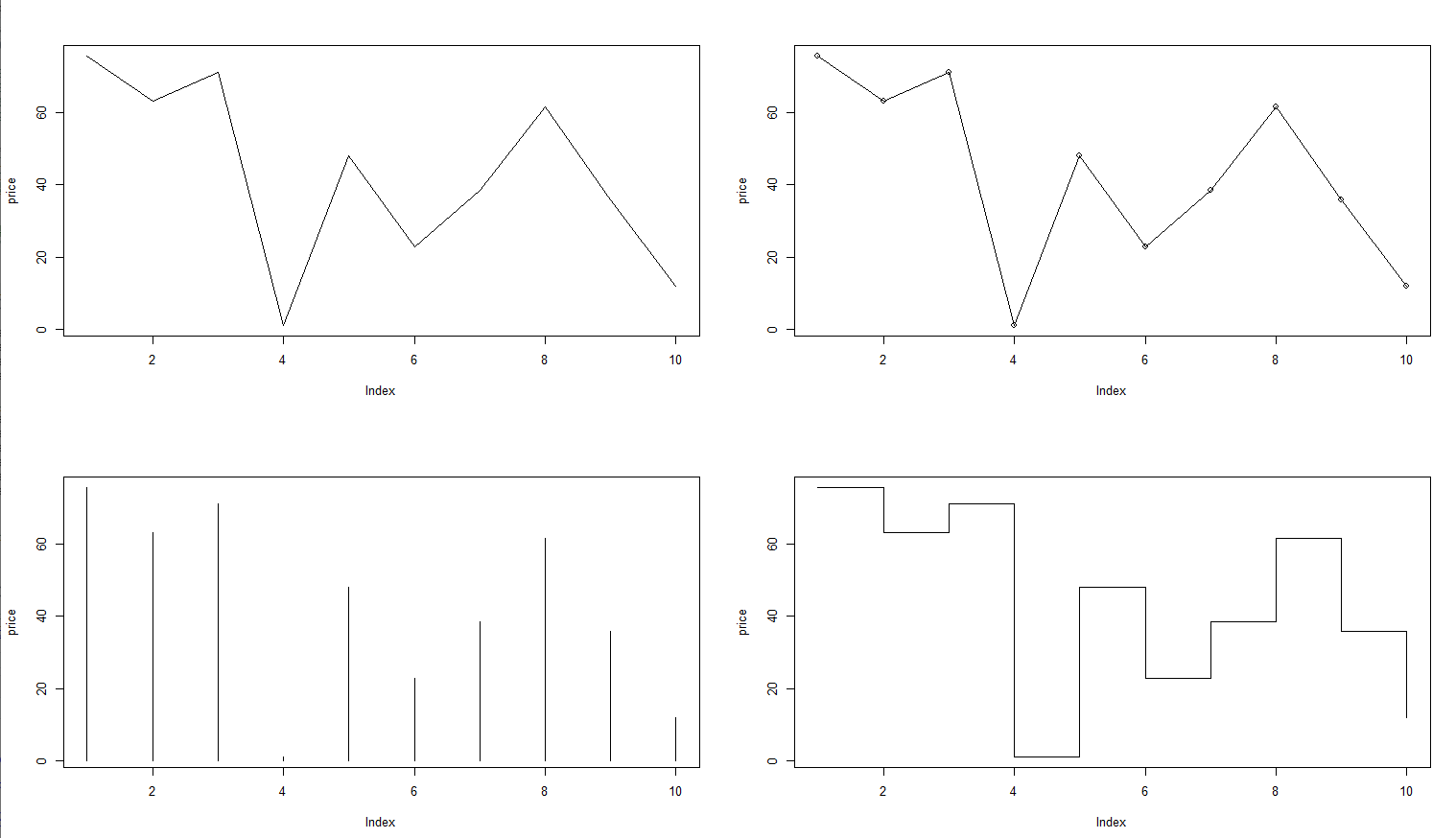
① type 속성 그리기
par(mfrow=c(2,2)) # 2행 2열 차트 / 4개의 이미지를 한번에 볼 수 있도록 셋팅
plot(price, type = "l") - 유형 : 실선
plot(price, type = "o") - 유형 : 원형과 실선(원형통과)
plot(price, type = "h") - 유형 : 직선
plot(price, type = "s") - 유형 : 꺾은선
② pch 속성으로 그리기
plot(price, type = "o", pch = 5) - 빈 사각형
plot(price, type = "o", pch = 15) - 채워진 사각형
plot(price, type = "o", pch = 20) - 채워진 원형
plot(price, type = "o", pch = 20, col = "blue") - 파란 채워진 원형
plot(price, type = "o", pch = 20, col = "orange", cex = 3.0) - 오랜지색 으로 채워진 원형(x3)
plot(price, type = "o", pch = 20, col = "orange", cex = 3.0, lwd=3)
- lwd : line width (선의 너비)


4) 중첩 자료 시각화
- 두 개의 벡터 객체 -
x <- c(1,2,3,4,2,4)
y <- rep(2,6) # rep(시작과 끝 : 반복 횟수
x;y
출력값 : [1] 1 2 3 4 2 4
출력값 : [1] 2 2 2 2 2 2
- 교차테이블 작성 -
table(x) - table : 빈도수
출력값 : 1 2 3 4
출력갑 : 1 2 1 2
table(y)
출력값 : 2
출력값 : 6
table(x,y)
- 출력값 -
y
x 2
1 1
2 2
3 1
4 2
x가 1일 때, y가 2인 값 = 1, x가 2일 때, y가 2인 값 = 2 ,
x가 3일 때, y가 2인 값 = 1, x가 4일 때, y가 2인 값 = 2
- 산점도 시각화 -
plot(x,y)
x가 1,2,3,4 일 때 y는 2 - 4개의 데이터만 있는 것으로 보인다
(데이터의 개수가 시각적으로 확인하기 어렵다)
# 중복된 만큼 점 확대 하기
- 데이터 프레임 생성 -
xy.df <- as.data.frame(table(x,y))
xy.df
- 출력값 -
x y Freq
1 2 1
2 2 2
3 2 1
4 2 2
- 좌표에 중복된 수 만큼 점 확대 -
plot(x,y,pch = 20 , col = "black", xlab = "x 벡터 원소" ,
ylab= "y 벡터 원소" , cex = 0.8 * xy.df$Freq) pch : 출력해주는 점의 모양 변경
col : 색상
xlab : x 레이블 이름
ylab : y 레이블 이름
cex : 점의 크기 - cex = 0 * 8 = xf.df$Freq // 빈도수를 곱해서 중복되었을 때 배가 되도록 합니다.

'빅데이터 > R' 카테고리의 다른 글
| [R] dplyr 패키지 (2) | 2020.07.03 |
|---|---|
| [R] plyr 패키지 (0) | 2020.07.02 |
| [R] 이산변수 시각화 (0) | 2020.07.01 |
| [R] 주요 내장 함수 (0) | 2020.07.01 |
| [R] 사용자 정의 함수 (0) | 2020.06.30 |