
Practice makes perfect
[BIGDATA Platform] 실시간 분산 처리기 : 스톰(STORM) 본문
스톰(STORM)이란?
: 실시간 분산 처리기 - 빅데이터 프로젝트에서 실시간 데이터를 병렬 프로세스(독자적으로 처리(MAP)의 결과를 최종의 결과로 모아주는 것 = reduce - 분산 병렬 처리 )로 처리하기 위한 소프트웨어입니다. Nathan Marz와 BacType의 팀이 개발하였으며, 이 프로젝트는 트위터에 의해 인수된 뒤 오픈 소스화되었습니다.

스톰의 특징
1) 스톰은 사용자가 만든 spout와 bolt를 사용하여 정보원과 조작부를 정의함으로써 스트리밍 데이터의 일괄, 분산 처리를 가능케 합니다.
2) 이벤트를 발생하게 하는 기능을 없어서 에스터를 연결하여 이벤트를 사용합니다.
* 에스퍼 : 실시간 스트리밍(데이터가 움직이는 통로) 데이터의 복잡한 이벤트 처리가 필요할 때 사용하는 룰 엔진
3) 심플 프로그래밍 모델 : 맵리듀스가 병렬처리 프로세싱 구현의 복잡도를 낮춰주는 것과 같이 스톰 또한 분산 real-time 프로세싱 구현의 복잡도를 낮춰줍니다.
4) 빠른 속도 : 인메모리 기반으로 실기간 처리 방식을 가지고 있습니다.
5) 다양한 언어로 구현 가능: 어떤 언어든 사용자가 익숙한 언어를 이용해 구현할 수 있다. 클로저(Clojure), 자바, 루비, 파이썬을 기본으로 제공하며 그 밖에 언어도 Storm communication protocol의 구현만으로도 사용이 가능합니다.
스톰의 아키텍처
1) Nimbus 와 Supervisor
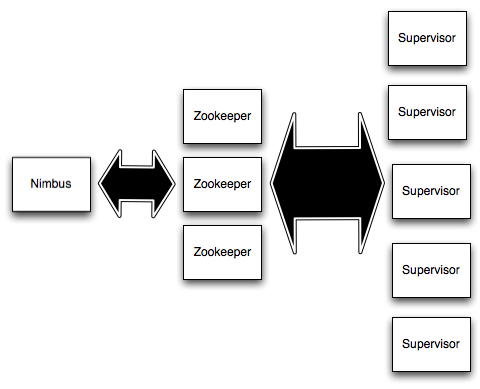
Nimbus가 Toplogy를 zookeeper를 통해서 Supervisor에 전달합니다.
Topology : spout, bolt의 데이터 처리 흐름을 정의 , 하나의 spout과 다수의 bolt로 구성 - 스톰의 연결 또는 구성 방법의 정보라고 할 수 있습니다.
Superviso : Topology를 실행할 worker를 구동시키며 topology 를 worker에 할당 및 관리하는 역할을 합니다.
2) Nimbus -> zookeeper -> Supervisor -> worker
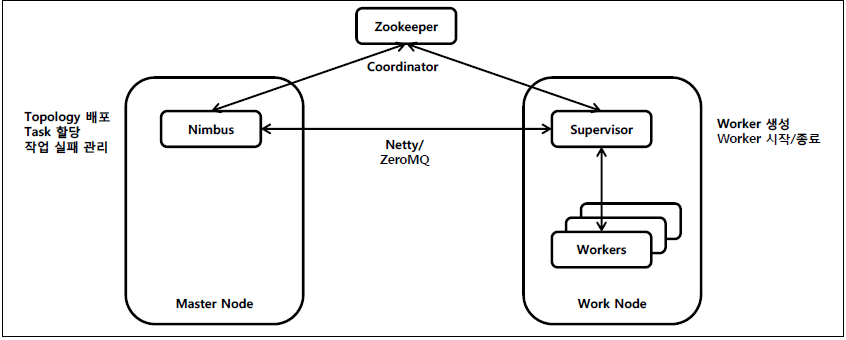
1)에서 과정 이후 woker를 할당합니다.
Worker: supervisor 상에서 실행중인 자바 프로세스로 spout과 bolt 를 실행하고 executor 관리하는 역할을 합니다.
3) Nimbus -> zookeeper -> Supervisor -> worker -> Executor
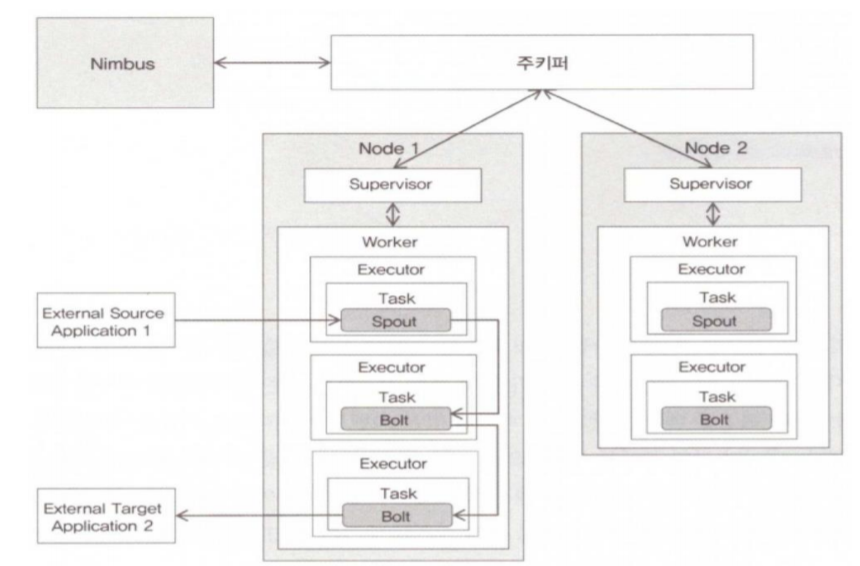
2) 이후 Executor을 할당해주고 Executor가 tasker를 할당해 줍니다.
Executor: worker 내에서 실행되는 자바 스레드의 역할을 하며, tasker영역을 할당해줍니다.
Tasker: spout 및 bolt 객체가 할당해주고 직접적인 작업의 영역입니다.
Spout: 데이터를 입력 받아 가공처리해서 튜플(스톰이 사용하는 자료형)을 생성 이후 해당 튜플을 bolt에 전송합니다.
Bolt: 튜플을 받아 실제 분산 작업을 수행하며, 필터링, 집계, 조인등의 연산을 병렬로 실행합니다.
순서)
: ) Nimbus -> zookeeper -> Supervisor -> worker -> Executor -> tasker -> spout -> Bolt
Nimbus에 의해서 정의한 것을 Topology에 정의하고 그 내용을 zookeeper를 통해서 supervisor 에 전해주고 Topology 의 정의에 맞게 woker를 구동시키고 Executor을 할당한 다음 Executor가 내용들을 작업 할 tasker를 할당하여 tasker을 통해 spout과 bolt를 할당해주어 수행할 수 있도록 해줍니다.
'빅데이터 > BIGDATA Platform' 카테고리의 다른 글
| [BIGDATA Platform] 빅데이터 실시간 적재 기술 : 레디스(Redis) (0) | 2020.06.12 |
|---|---|
| [BIGDATA Platform] 빅데이터 실시간 적재 기술 : HBase (0) | 2020.06.12 |
| [BIGDATA Platform] 빅데이터의 핵심 소프트웨어 : 하둡(Hadoop) (0) | 2020.06.11 |
| [BIGDATA Platform] 분산 코디네이터 : 주키퍼(ZOOKEEPER) (0) | 2020.06.11 |
| [BIGDATA Platform] 빅데이터 수집의 기술 : 카프카(Kafka) (0) | 2020.06.10 |



