
Practice makes perfect
[BIGDATA Platform] 빅데이터 탐색 기술 : 스파크(Spark) 본문
스파크(Spark)란?
: 빅데이터 워크로드에 주로 사용되는 분산처리 기능을 제공하는 하둡과 마찬가지로 오픈소스입니다. 특징은 빠른 성능을 위해 인 메모리 캐싱과 최적화된 실행을 사용하고 일반 배치 처리, 스트리밍 분석, 머신러닝, 그래프 데이터 베이스 및 임시 쿼리를 지원합니다.

아파치 스파크 홈페이지 : spark.apache.org/
맵리듀스 코오를 그대로 사용하는 하이브는 성능면에서 만족스럽지 못했으며, 그로 인해 반복적인 대화형 연산 작업에서는 하이브가 적합하지 못합니다. 이러한 단점을 극복한 고성능 인메모리 위에서 분석함으로써 대용량 데이터 작업에도 빠른 성능을 보장합니다.
하둡과 하이브를 비롯한 기존의 여러 솔루션과의 연동(스칼라, 자바, 파이썬, R)을 지원하고 마이크로 배치 방식의 실시간 처리 및 머신러닝 라이브러리를 비롯해 빅데이터 처리와 관련된 다양한 라이브러리를 지원합니다
* 스칼라 : 융통성, 유연성, 데이터 분석에 적합한 함수형 프로그래밍 개념을 사용할 수 있는 특징을 가지고 있습니다.
스파크(Spark)의 기능
- 빅데이터 애플리케이션에 필요한 대부분의 기능을 지원합니다.
- 맵리듀스와 유사한 일괄 처리 기능
- 실시간 데이터 처리 기능 (Spark Streaming)
- SQL과 유사한 정형 데이터 처리 기능 (Spark SQL)
- 그래프 알고리즘(Spark GraphX)
- 머신 러닝 알고리즘(Spark MLlib)
스파크(Spark) 단점
: 데이터 셋이 적어서 단일 노드로 충분한 애플리케이션에서 스파크는 분산 아키텍처로 인해 오히려 성능이 떨어질 수 있습니다. 또한 대량의 트랜잭션을 빠르게 처리해야 하는 애플리케이션은 스파크가 온라인 트랜잭션 처리를 염두에 두고 설계되지 않았기 때문에 유용하지 않을 수 있습니다.
스파크(Spark) 아키텍처
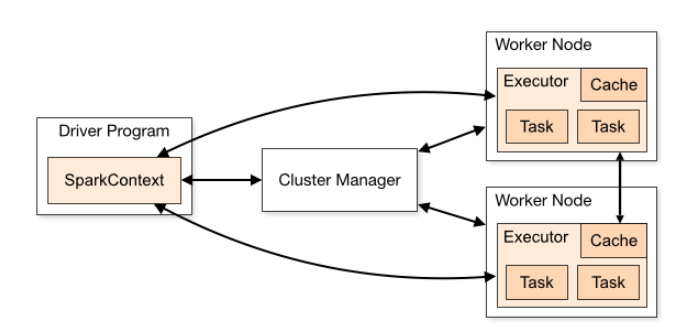
스파크는 일반적으로 "Driver Program"이라고 하는데, 이 Driver Program 은 여러 개의 병렬적인 작업으로 나뉘어서 Spark의 Worker Node에 있는 Executor에서 실행합니다.
SparkContext가 SparkClusterManager에 접속합니다. 이 클러스터 매니저는 스파크 자체의 클러스터 메니져가 될 수 도 있고 Mesos, YARN 등이 될 수 있습니다. 이 클러스터 매니저를 통해서 가용한 Excutor 들을 할당받습니다.
↓
Excutor를 할당받으면, 각각의 Executor들에게 수행할 코드를 보냅니다.
↓
다음으로 각 Excutor 안에서 Task에서 로직을 수행합니다.
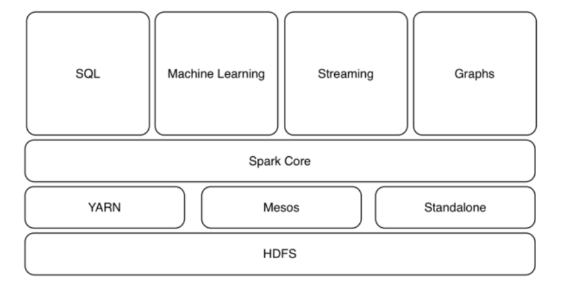
주요 구성 요소
Spark Core : 스파크 잡과 다른 스파크 컴포넌트에 필요한 기본 기능을 제공, 특히 분산 데이터 컬렉션을 추상화 한 객체인 RDD로 다양한 연산 및 변환 메소드를 제공합니다. RDD는 노드에 장애가 발생해도 데이터 셋을 재구성할 수 있는 복원성을 가지고 있습니다. 쉽게 이야기해서 하둡과 같은 일괄처리 담당하며 다른 프래임워크의 기반이다.
Spark RDD : 스파크 프로그래밍의 기초 데이터셋 모델, 데이터 내장애성 보유 구조, 데이터 집합의 객체 개념
Spark Driver / Executors : Driver는 RDD 프로그램을 분산 노드에서 실행하기 위한 Task의 구성, 할당, 계획 등을 수립하고 , Executor는 Task를 실행 관리하며, 분산 노드의 스토리지 및 메모리를 참조
Spark Cluster Manager : 스파크 실행 환경을 구성하는 클러스터 관리자로 Mesos, YARN , Spark Standalone이 있음
Spark SQL : SQL 방식으로 스파크 RDD 프로그래밍을 지원
Spark Streaming : 스트리밍 데이터를 마이크로 타임의 배치로 나누어 실시간 처리
Spark MLib : 스파크에서 머신러닝 프로그램(군집, 분류, 추천 등)을 지원
Spark GraphX : 다양한 유형의 네트워크(SNS, 하이퍼링크 등) 구조 분석을 지원, 그래프는 정점과 두 정점을 잇는 간선으로 구성된 데이터 구조이며, 그래프 RDD 형태의 그래프 구조를 만들 수 있는 기능을 제공합니다.
스파크(Spark) vs 스톰(Storm)
| 항목 | 스파크 | 스톰 |
| 데이터 처리 | 일괄 처리 방식 | 실시간 스트리밍 방식 |
| 업데이트 | 파일 or 테이블 | 스트림(튜플) |
| 컴퓨터 환경 | 인메모리 기반 | 인메모리 기반 |
| 반복 작업 | 강력한 성능 | 일반적 수준 |
| 프러그램 언어 | Scala | Clojure |
| 사용 환경 | 반복 & 많은 연산 | 응답시간 ↓ , 다양질의 |
'빅데이터 > BIGDATA Platform' 카테고리의 다른 글
| [BIGDATA Platform] 빅데이터 탐색 활용 소프트웨어 : Hue (1) | 2020.06.18 |
|---|---|
| [BIGDATA Platform] 스케줄링 시스템 : 우지(Oozie) (0) | 2020.06.18 |
| [BIGDATA Platform] 빅데이터 탐색 기술 : 하이브(Hive) (1) | 2020.06.17 |
| [BIGDATA Platform] 빅데이터 실시간 적재 기술 : 레디스(Redis) (0) | 2020.06.12 |
| [BIGDATA Platform] 빅데이터 실시간 적재 기술 : HBase (0) | 2020.06.12 |



