
Practice makes perfect
[R] 개요3 (변수2 , factor 함수) 본문
R , 파이선이 데이터 분석에서 부각이 된 이유 무엇일까요?
그 이유는 분석 관련 알고리즘을 보게 되면 모든 이론들이 머신러닝이라는 이름 하에 엄청나게 많은 연산이 이루어집니다. 이러한 데이터의 형태가 숫자를 통해서 결과를 도출하는 알고리즘이기 때문에 실직적으로 알고리즘에 적용될 때는 수치형으로 변환시켜 알고리즘에 넣어서 학습을 통해 결과를 도출하기 때문에 별도의 자료형을 가지고 있지 않아도 됩니다. 이러한 이유로 데이터 분석에서 부각되어지고 있다고 합니다.
R 변수의 특징
R은 데이터를 담아주는 구분이 없기 때문에 변수 안에는 컴퓨터가 인식할 수 있는 데이터를 변수의 이름만 선언을 해주면 모든 데이터를 담을 수 있는 특징을 가지고 있습니다. 이러한 기능 가능한 이유는 동적 할당 언어(동적 프로그래밍 언어)로, 변수의 데이터를 담을 때 담는 순간 자료형이 결정되집니다.
R 의 단점
클라이언트의 요청, 요구에는 각각 고유의 특징을 가지고 있습니다. 이러한 것을 분석의 결과로 가져올 수 있게 모든 알고리즘이 제공해주지는 못합니다. 목표점을 가지고 분석결과에 맞춰서 데이터셋을 가지고 결과를 도출해야 합니다. 그렇기 때문에 전처리 작업에 있어서 프로그래밍 능력을 요구 합니다. 이러한 전처리 부분에 있어서 R, 파이썬으로는 가독성이 떨어지면 기능 구현에 있어서 불편한 점들이 존재합니다. 이러한 이유로 실질적인 내부 로직을 구현하기 위해서는 c , c++ , java 를 통해서 결과를 수행합니다.
객체지향이란 무엇일까요?
제가 생각하는 객체지향이란, 객체지향 하나하나로 바라보는 것이 아니라 레코드를 하나의 객체로 바라보는 것입니다. java 에서 하나의 변수의 이름으로 관리하는 것이 참조자료형의 선언이었고, 이게 객체지향이 프로그램 안에서 적용되었던 방법이었습니다. 즉, 데이터를 하나씩 바라보는 것에서 레코드 단위로 하나의 변수의 이름을 가지고 관리하는 것을 의미합니다. R 또한 객체지향 언어이므로 객체지향의 개념을 명확하게 아는것이 중요합니다.
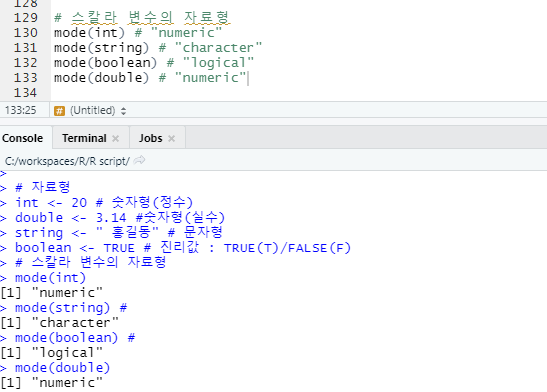
# 스칼라 변수 : 하나의 데이터만을 저장한 변수

# 스칼라 변수의 자료형
자료형을 반환해주는 함수 : mode()
# 벡터 변수 : 두개 이상의 데이터를 담고 있는 변수

# 문자 벡터와 그래프 생성
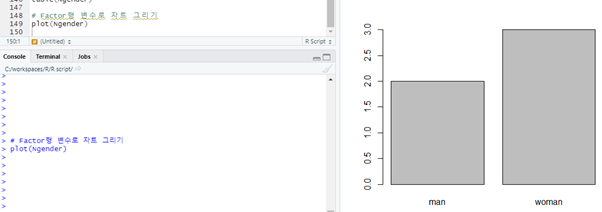
시각화 해주는 함수(빈도수) : plot()

error : plot() 함수는 숫자 자료만을 대상으로 그래프를 생성할 수 있습니다.
# 요인형 변환 : as.factor() 함수 이용 범주(요인)형 변환
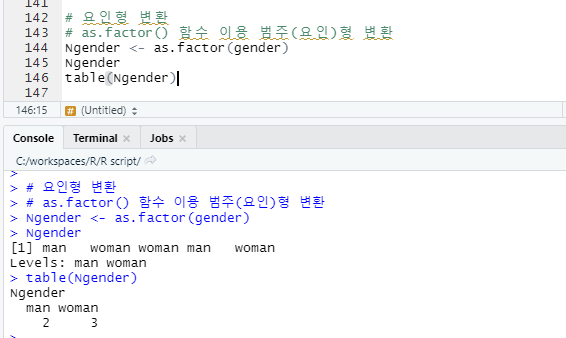
Database의 도메인의 개념 : 컬럼항목이 가질 수 있는 값 / ex) 성별 – 남,여(도메인) 이러한 개념을 R에서 범주라는 개념으로 사용합니다.
# Factor형 변수로 차트 그리기
# 자료구조에 대한 정보 확인 함수 : class

# factor() 함수 이용 Factor형 변환

매개 변수(parameter)가 6개로 정의되어 있어도 다양한 형태로 함수를 호출할 수 있도록 호출 형태를 제공해 줍니다.
function (x = character(), levels, labels = levels, exclude = NA,
ordered = is.ordered(x), nmax = NA)
x = character() x에 값이 전달되어지면 바로 저장되고, 값이 저장되지 않으면 초기화 되기때문에 아무 값을 넣지 않아도 출력합니다.
labels = levels, exclude = NA, ordered = is. ordered(x), nmax = NA 값을 넣지 않아도 초기화 해줍니다.
levels의 값만 넣어주면 문제없이 출력합니다.
levels에는 초기화 값이 없기 때문에 값을 넣어주지 않으면 error가 발생

또한 매개 변수의 순서가 중요하지 않으며, 각각의 이름을 붙이기 때문에 문제없이 출력합니다.

원칙적으로는 error가 나타나야 할 것 같은데 error 가 나지 않는 이유는?
|
levels |
an optional vector of the unique values (as character strings) that x might have taken. The default is the unique set of values taken by as.character(x), sorted into increasing order of x. Note that this set can be specified as smaller than sort(unique(x)). |
: x에 전달되는 데이터를 character로 형 변환해서 사용하기 때문입니다.
factor(x = character(), levels, labels = levels, exclude = NA, ordered = is.ordered(x), nmax = NA) ordered(자동 정렬)(x, ...): 알파벳 순서, 가나다 순, 123순으로 나열합니다.
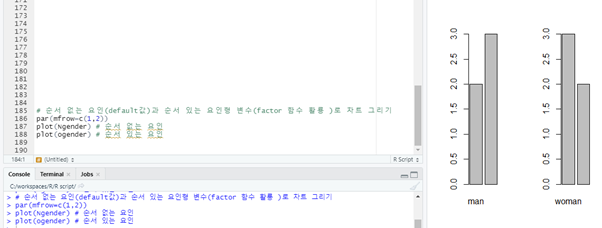
# 순서 없는 요인(default값)과 순서 있는 요인형 변수(factor 함수 활용)로 차트 그리기
# 함수의 parameter 보여주는 함수 : args()

# 함수 사용 예제를 보여주는 함수 : example()

# 작업 공간 확인 , 변경
getwd() = 작업 공간 확인
setwd() = 작업 공간 변경, 하지만 R studio가 꺼지면 초기값으로 돌아옵니다.

# 도움말 보기 – RStudio를 사용하면 함수에 대한 자세한 설명을 볼 수 있다.
# 복소수형 : 실수 와 허수가 함께 사용 된 수치의 형태 / 허수 독자적으로만 표현 되어도 문제x
허수 : 제곱하여 -1이 되는 수를 허수단위라 하고 기호로 i와 같이 나타냅니다.

'빅데이터 > R' 카테고리의 다른 글
| [R] 주요 자료 구조(객체 타입 Part_2 : Matrix구조) (0) | 2020.06.24 |
|---|---|
| [R] 주요 자료 구조(객체 타입 Part_1 : Vector 구조) (0) | 2020.06.23 |
| [R] 개요2 (변수) (0) | 2020.06.23 |
| [R] R 개요 (0) | 2020.06.22 |
| [R] R Studio 다운로드 (0) | 2020.06.22 |



