
Practice makes perfect
[R] 텍스트 마이닝 분석 - 연관어 분석(단어 연관성) 본문
연관어 분석(단어 연관성)
: 연관 알고리즘을 통해서 단어 사이의 관계를 파악해서 시각화 하는 분석 방법입니다.
- 연관 분선은 대표적인 비지도 학습의 알고리즘으로 구성되어 있습니다.
※ 지도 학습 : 데이터와 결과를 알려주면서 학습 시키는 방법
※ 비지도 학습 : 데이터는 주지만 결과를 주지 않고 스스로 학습 하도록 만드는 방법
- 시각화: 연관어 네트워크 시각화와 근접 중심성
ⓘ 한글 처리를 위한 패키지 설치 (토픽 분석과 동일)
install.packages("KoKLP") # package ‘KoKNP’ is not available (for R version 4.0.1)
install.packages("https://cran.rstudio.com/bin/windows/contrib/3.4/KoNLP_0.80.1.zip",repos = NULL)
# repos = NULL : 버전은 다운한 3.6버전에 설치한다든 옵션
# Sejong 설치 : KoNLP 와 의존성 있는 현재 버전의 한글 사전
# Sejong 패키지 설치
install.packages("Sejong")
install.packages(c("hash","tau","RSQLite","rJava","devtools"))
library(Sejong)
library(hash)
library(tau)
library(RSQLite)
Sys.setenv(JAVA_HOME='C:/Program Files/Java/jre1.8.0_221')
library(rJava) # rJava를 올리기 전에 java의 위치를 지정해줘햔다.
library(devtools)
library(KoNLP)
market.txt 를 활용하여 살펴보도록 하겠습니다.

② 텍스트 파일 가져오기와 단어 추출하기
marketing <- file("C:/workspaces/R/data/marketing.txt", encoding = "UTF-8")
marketing2 <- readLines(marketing) # 줄 단위 데이터 생성
marketing2[1]
③ 줄 단위 단어 추출
lword <- Map(extractNoun, marketing2) # Map(extractNoun,변수) :변수에서 명사단위로 추출
length(lword) 출력값: [1] 472 : 라인별로 472개를 가지고 있다.
lword <- unique(lword) # 빈 block 필터링
length(lword) 출력값 : [1] 353 : 중복 단어를 제거 이후, 353개를 가지고 있다.
str(lword) # List of 353
- 출력값 -
$ : chr [1:20] "본고" "목적" "비판이론" "토대" ...
$ : chr [1:19] "전통" "적" "마케팅" "욕구충족" ...
head(lword)
- 출력값 - 
④ 단어 필터링 함수 정의
- 길이가 2개 이상 4개 이하 사이의 문자 길이로 구성된 단어
filter1 <- function(x){
nchar(x) >= 2 && nchar(x) <=4 && is.hangul(x)
} # 자동적으로 영어가 필터링
filter2 <- function(x){
Filter(filter1, x)
}
⑤ 줄 단위로 추출된 단어 전처리
lword <- sapply(lword, filter2) # 단어 길이 1이하 또는 5이상인 단어 제거
head(lword)

2 ~ 4사이의 단어출력 ( 1이하 또는 5이상 단어 제거(한글 외 언어 제거))
⑥ 트랜잭션 생성
- 트랜잭션 : 연관분석에서 사용되는 처리 단위.
- 연관분석을 위해서는 추출된 단어를 대상으로 트랜잭션 형식을 자료구조 변환.
- 토픽 분석 Corpus() : 단어 처리의 단위
- 연관분석을 위한 패키지 설치
install.packages("arules")
library(arules)
- 트랜잭션 생성
wordtran <- as(lword, "transactions")
wordtran
- 출력값 -
transactions in sparse format with
353 transactions (rows) and
2423 items (columns)as() 를 통해서 transactions 를 넣으면 내부에서 효율적으로 처리되도록 트랜잭션으로 변환해줍니다.
⑦ 교차평 작성 : crossTable() -> 교차테이블 함수를 이용
wordtable <- crossTable(wordtran)
wordtable
유사 단어들이 함께 있는 형태로 출력(transaction)
⑧ 단어 간 연관 규칙 산출
transrlues <- apriori(wordtran, parameter = list(support=0.25,conf =0.05))
출력값 : writing ... [59 rule(s)] done [0.00s]. (59개의 규칙을 찾았다.)
apriori() : 연관분석 기능 적용(규칙성을 찾음) , 자료구조의 형태는 transaction 일때 정상적으로 실행
support = 지지도 : 수치형의 값(상관도) = 퍼센트 값으로 최대값 1, 최소값 0
전체 거래에서 특정 물품 A와 B가 동시에 거래되는 비중으로,해당 규칙이 얼마나 의미가 있는 규칙인지를 보여줍니다. 지지도 = P(A∩B) : A와 B가 동시에 일어난 횟수 / 전체 거래 횟수
conf = 신뢰도
A를 포함하는 거래 중 A와 B가 동시에 거래되는 비중으로, A라는 사건이 발생했을 때 B가 발생할 확률이 얼마나 높은지를 말해줍니다.
신뢰도 = P(A∩B) / P(A) : A와 B가 동시에 일어난 횟수 / A가 일어난 횟수
⑨ 연관 규칙 생성 결과 보기
inspect(transrlues)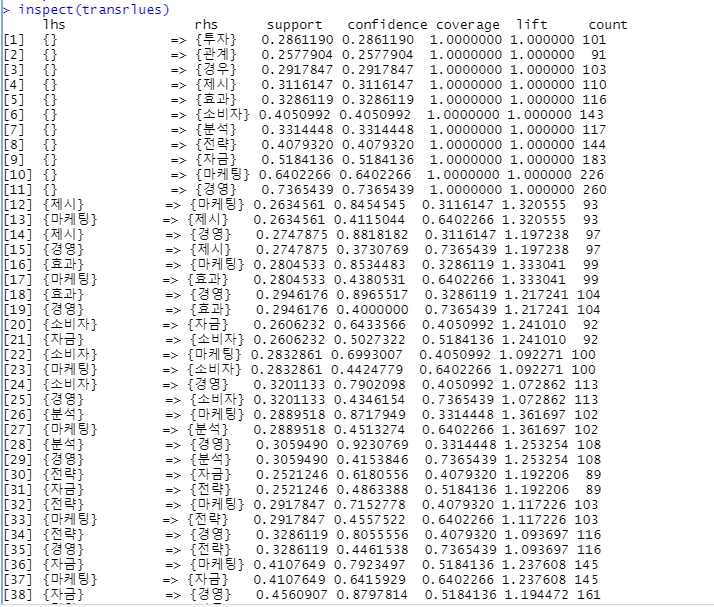
⑩ 연관어 시각화
- 연관 단어 시각화를 위해서 자료 구조 변경
rules <- labels(transrlue, ruleSep = " ") # 연관규칙 레이블을 " "으로 분리
head(rules,20)
- 문자열로 묶인 연관 단어를 행렬 구조 변경
rules <- sapply(rules, strsplit, " ", USE.NAMES = F)
rules
class(rules) # [1] "character" -> [1] "list"
- 행 단위로 묶어서 matrix로 반환 (do.call)
rulemat <- do.call("rbind", rules)
rulemat
class(rulemat) # [1] "matrix"
- 연관어 시각화를 위한 igraph 패키지 설치
install.packages("igraph")
library(igraph)
- edgelist 보기 - 연관 단어를 정점(vertex) 형태의 목록 제공 (matrix 형태의 자료형을 전달 받게 되어 있음)
relueg <- graph.edgelist(rulemat[c(12:59),],directed = F) # [c(1:11)] - "{}" 제외
relueg

- edgelist 시각화
plot.igraph(relueg)
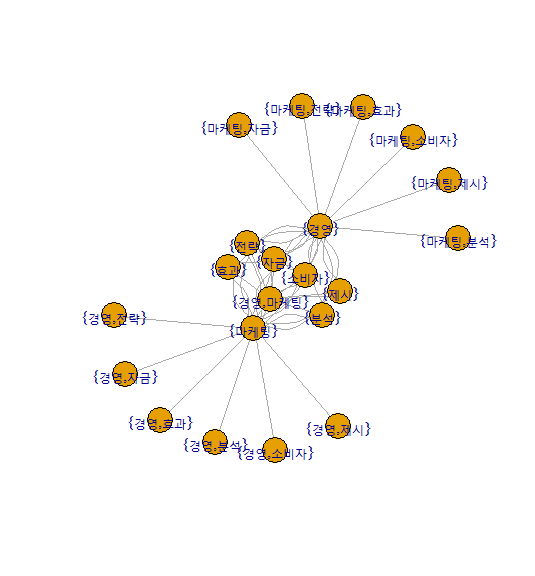
- edgelist 시각화 part_2
plot.igraph(relueg,vertex.label=V(relueg)$name, vertex.label.cex=1.2,vertex.label.color='black',
vertex.size=20, vertex.color='green',vertex.frame.color = 'blue') 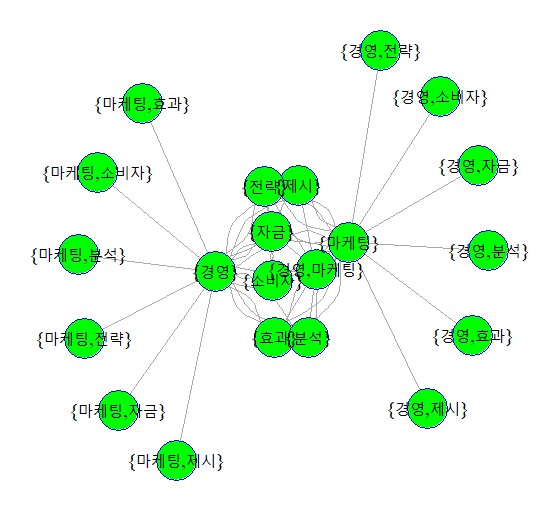
해석 : 거리가 가까울수록 높은 연관성을 가지고 있음을 보여줍니다.
경영과 마케팅과의 연관성
# - 참조(unique())
c1 <- rep(1:10 , each=2) # rep : vector 객체 생성
c1 출력값 : [1] 1 1 2 2 3 3 4 4 5 5 6 6 7 7 8 8 9 9 10 10
c2 <- rep(c(1,3,5,7,9),each=4) # 1,3,5,7,9 반복 vector 객체 생성
c2 출력값 : [1] 1 1 1 1 3 3 3 3 5 5 5 5 7 7 7 7 9 9 9 9
c3 <- c(1,1,1,1,3,3,3,3,5,5,6,6,7,7,8,8,9,10,11,12)
c3 출력값 : [1] 1 1 1 1 3 3 3 3 5 5 6 6 7 7 8 8 9 10 11 12
c123_df <- data.frame(cbind(c1,c2,c3))
c123_df
# cbind : 열 단위로 묶어서 데이터 프레임으로 만듬
str(c123_df) # 'data.frame': 20 obs. of 3 variables:
c12_unique <- unique(c123_df[,c("c1", "c2")]) # 행을 지정하지 않으면 20개 전체가 출력
c12_unique
# 중복(입력하는 대상이 두개 다 같을 때) 되는 값은 제거하고 출력
c123_unique <- unique(c123_df[,c("c1", "c2","c3")]) # 행을 지정하지 않으면 20개 전체가 출력
c123_unique
# 나중에 등장하는 값이 제거 되는 것이 default 값
c123_unique <- unique(c123_df[,c("c1", "c2","c3")],fromLast=T) # 행을 지정하지 않으면 20개 전체가 출력
c123_unique
# fromLast= F(default) : 뒤에 나오는 값이 제거 , fromLast= T : 앞에 나오는 값 제거
- c123_df

- c12_unique

- c123_unique

- c123_unique(+fromLast =T)

'빅데이터 > R' 카테고리의 다른 글
| [R] 텍스트 마이닝 분석 - 실시간 뉴스 수집과 분석 (1) | 2020.07.13 |
|---|---|
| [R] 통계 분석 절차 (0) | 2020.07.10 |
| [R] 텍스트 마이닝 분석 (토픽분석) (7) | 2020.07.09 |
| [R] 텍스트 마이닝 분석 - 개요, 토픽 분석 설치 및 환경설정 (0) | 2020.07.09 |
| [R] 정형 데이터 처리(DB 연결) (0) | 2020.07.08 |


