
Practice makes perfect
[R] 텍스트 마이닝 분석 - 실시간 뉴스 수집과 분석 본문
크롤링(crawling) 혹은 스크래핑(scraping)은 웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위로, 크롤링하는 소프트웨어는 크롤러(crawler)라고 부릅니다.
무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술. 어느 부류의 기술을 얼마나 빨리 검색 대상에 포함시키냐 하는 것이 우위를 결정하는 요소로서 최근 웹 검색의 중요성에 따라 발전되고 있습니다.
관련 용어
(1) 웹크롤링(web crawling)
- 웹을 탐색하는 컴퓨터 프로그램(크롤러)를 이용하여 여러 인터넷 사이트의 웹 페이지 자료를 수집해서 분류하는 과정.
- 또한 크롤러(crawler)란 자동화된 방법으로 월드와일드웹(www)을 탐색하는 컴퓨터 프로그램을 의미.
(2) 스크래핑(scarping)
- 웹사이트의 내용을 가져와 원하는 형태로 가공하는 기술
- 즉 웹사이트의 데이터를 수집하는 모든 작업을 의미
- 결국, 크롤링도 스크래핑 기술의 일종
- 크롤링과 스크래핑을 구분하는 것은 큰 의미가 없음
(3) 파싱(parsing)
- 어떤 페이지(문서, HTML등) 에서 시용자가 원하는 데이터를 특정 패턴이나 순서로 추출하여 정보를 가공하는 것.
- 예를들면 HTML 소스를 문자열로 수집한 후 실제 HTML태그로 인식할 수 있도록 문자열을 의미있는 단위로 분해하고, 계층적인 트리 구조를 만드는 과정.
(1) 패키지 설치 및 준비
install.packages("tidyverse")
install.packages("rvest") # html 추출
library(tidyverse)
library(rvest)
start라는 값으로 페이지의 차이를 보입니다.
1 page : https://search.naver.com/search.naver?
&where=news&query=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&sm=tab_pge&sort=0&photo=0
&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&
mynews=0&cluster_rank=55&start=1&refresh_start=0
2 page : https://search.naver.com/search.naver?
&where=news&query=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&sm=tab_pge&sort=0&photo=0
&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&
mynews=0&cluster_rank=31&start=11&refresh_start=0
(2) url 요청
base_url <- "https://search.naver.com/search.naver?
&where=news&query=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&sm=tab_pge&
sort=0&photo=0&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&
mynews=0&cluster_rank=55&refresh_start=0&start="
# url의 순서는 중요하지 않고, 내용에 무엇이 담겨있는지가 중요.
# &start=1 값을 뒤로 보내고 1 값을 지움
# 1페이지 1, 2페이지 11, 3페이지 21 ...
- url 가져오기
urls <- NULL
for(x in 0:9){ #0~9까지 10개의 순차적인 값 출력(10번 반복)
urls <- c(urls, paste(base_url,x*10+1,sep= ''))
}
urls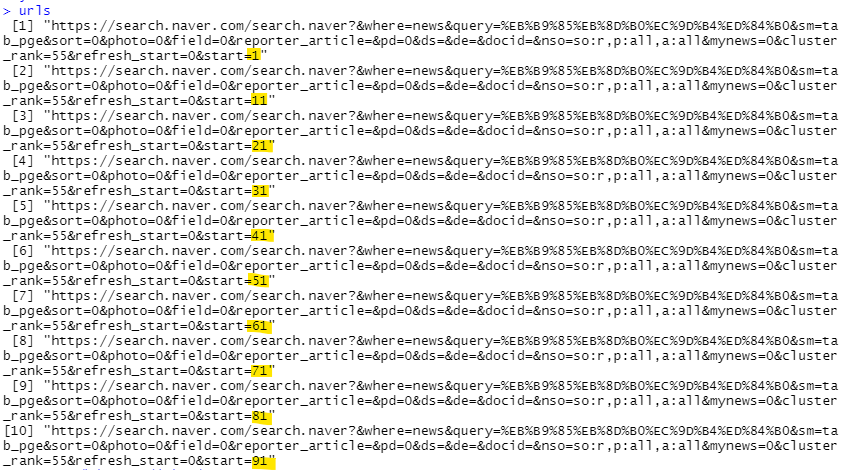
paste() : 여러 문자열을 연결시켜주는 함수.
(3) R에서 HTML 불러오기
html <- read_html(urls[1])
html
(4) HTML 에서 필요한 부분 뽑아오기
htmlnode <- html_nodes(html,'ul.type01 > li > dl > dd > a') # 첫페이지 네이버 뉴스 링크
# ( . ) 클래스 선택자 , ( > ) 자식 선택자
htmlnode
html_attr(htmlnode,'href') # href : url 주소만 읽어 옴 

혹은 위의 (3) ~ (4) 과정을 파이프 연상자를 이용해서 한번에 수행
urls[1] %>%
read_html() %>%
html_nodes('ul.type01 > li > dl > dd > a') %>%
html_attr('href')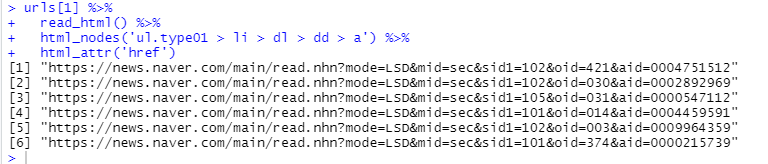
(5) 뉴스 기사 url 뽑아내기
news_links <- NULL
for(url in urls){
html <- read_html(url)
news_links <- c(news_links,html %>%
html_nodes('ul.type01 > li > dl > dd > a') %>%
html_attr('href')
)
}
news_links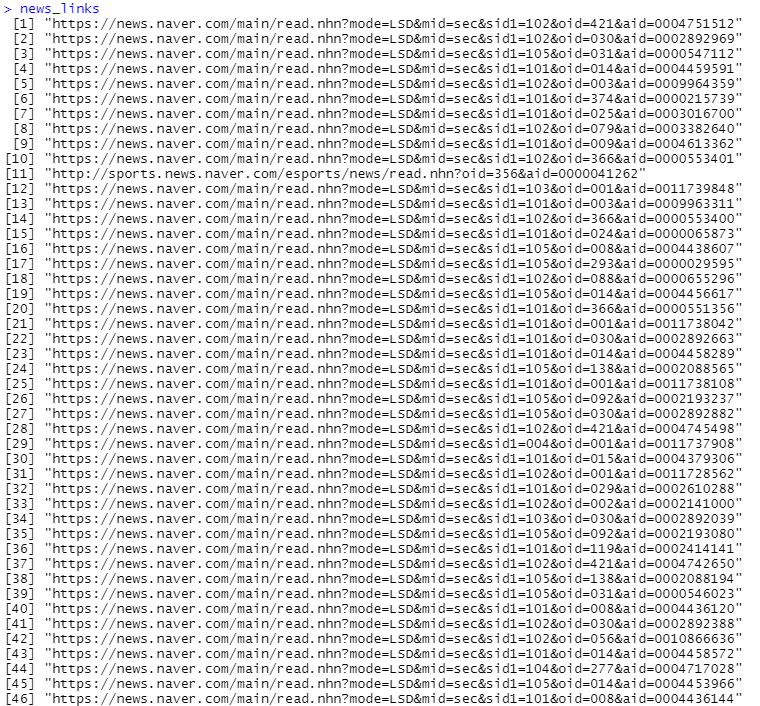
(6) 뉴스 본문/제목 추출하기
contents <- NULL
title <- NULL
# news_links - 59개의 링크
for(link in news_links){
html <- read_html(link)
# 본문
contents <- c(contents, html %>%
html_nodes('._article_body_contents') %>%
html_text())
# 제목
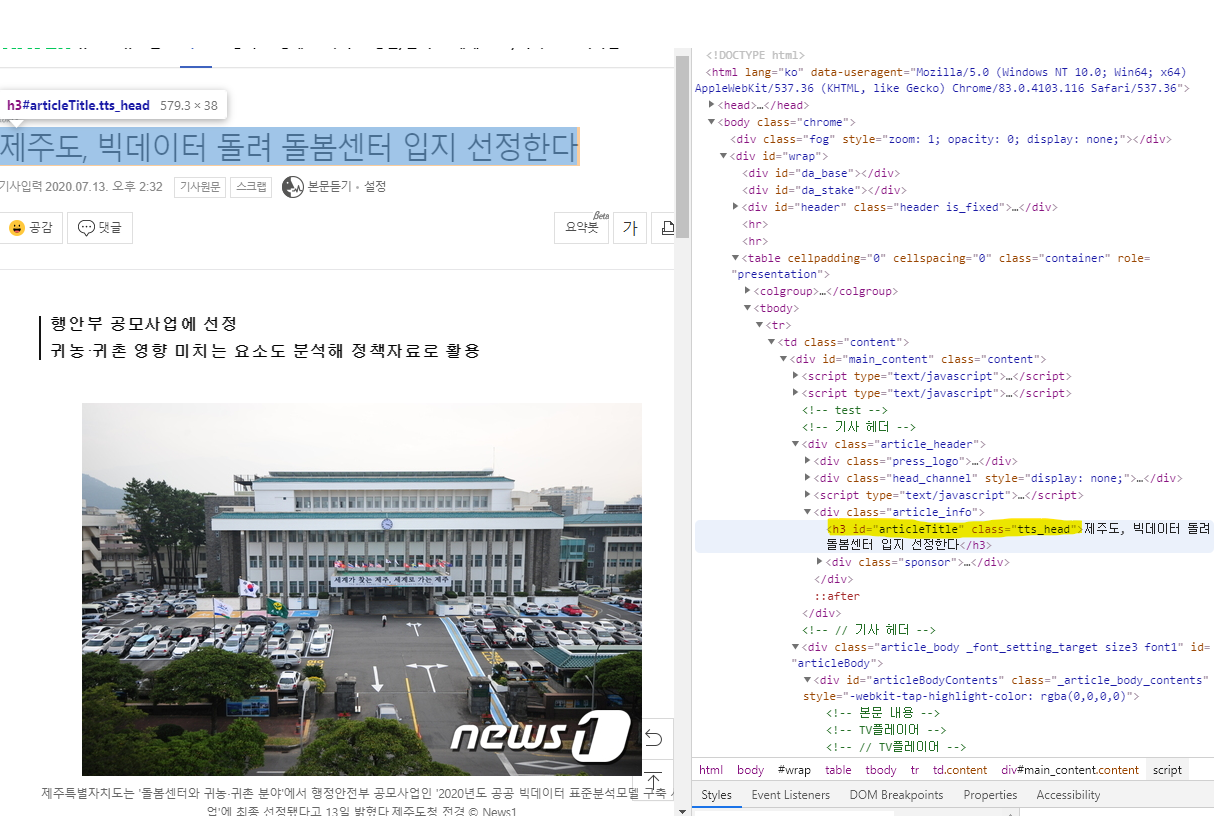
title <- c(title, html %>%
html_nodes('#articleTitle') %>%
html_text())
}
contents_df <- as.data.frame(contents)
title_df <- as.data.frame(title)
news<- cbind(title_df,contents_df) # 열중심으로 결함
View(news)( # ) id 선택자 , ( . ) class 선택자
본문 = class 이름으로 선택해야 전체 바디 영역이 선택됩니다.

본문 ('._article_body_contents')

제목 ('#articleTitle')
(7) 수집한 자료 전처리
- gsub("패턴", "교체문자",자료)
contents_pre <- gsub("[\r\n\t]",' ',contents) # 이스케이프 문자 제거
contents_pre <- gsub("[[:punct:]]",' ',contents_pre) # 문장 부호 제거
contents_pre <- gsub("[[:cntrl:]]",' ',contents_pre) # 특수 문자 제거
contents_pre <- gsub("\\d+",' ',contents_pre) # 숫자 제거
contents_pre <- gsub("[a-z]",' ',contents_pre) # 영문 소문자 제거
contents_pre <- gsub("[A-Z]",' ',contents_pre) # 영문 대문자 제거
contents_pre <- gsub("\\s+",' ',contents_pre) # 2개 이상 공백 교체
contents_pre[1]
'빅데이터 > R' 카테고리의 다른 글
| [R] 척도별 기술 통계량 구하기 (0) | 2020.07.14 |
|---|---|
| [R] 평균, 분산, 표준변차 (0) | 2020.07.13 |
| [R] 통계 분석 절차 (0) | 2020.07.10 |
| [R] 텍스트 마이닝 분석 - 연관어 분석(단어 연관성) (0) | 2020.07.10 |
| [R] 텍스트 마이닝 분석 (토픽분석) (7) | 2020.07.09 |

