ggplot2(기하학적 기법 시각화) : 그래프를 만들 때 사용하는 패키지로 'layer' 구조로 되어 있습니다.
- 기본(x,y축 설정) + 옵션1(그래프 유형선택 - 점, 선, 막대) + 옵션2 (색상, 표식 등등)
ggplot2 패키지 특징
※ qplot() : 옵션을 상세하게 지정하지 않아도 basic plot 보다 예쁘게 시각화 하고 싶을 때 사용
1) 패키지 설치와 실습 데이터 셋 가져오기 install.packages("ggplot2")
library(ggplot2)
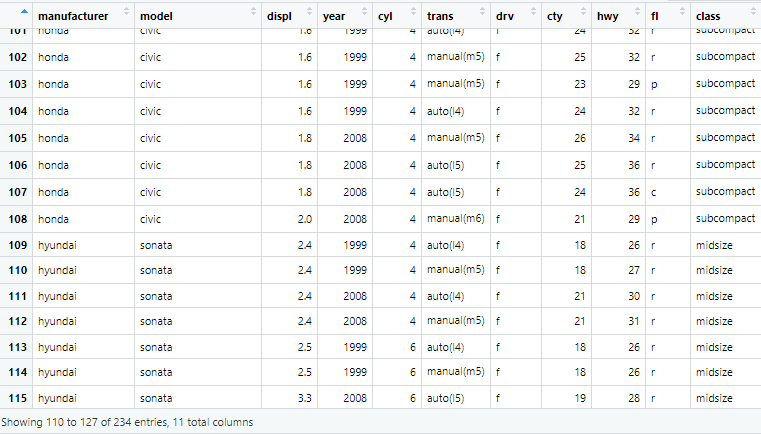
mpg 데이터
더보기
mpg 데이터 셋 ggplot2에서 제공하는 데이터 셋으로, 1999년부터 2008년 사이의 가장 대중적인 모델 38개 자동차에 대한 연비 효율을 기록한 데이터 셋으로 전체 관측 234개와 11개의 변수로 구성되어 있다.
주요 변수:
manufacturer(제조사)
model(모델)
displ(엔진 크기)
year(연식)
trans(변속기)
drv(구동 방식 : 사륜(4), 전륜(f), 후륜(r))
hwy(gallon당 고속 도로 주행 마일 수)
mpg 데이터를 활용하도록 하겠습니다.
2) gplot() gplot(x, y, data)함수 이용 플로팅
① 세로 막대 그래프 (default 값)
qplot(data = mpg, x = hwy)
고속도로 연비에 대한 분포도
② fill 속성 : hwy 변수를 대상으로 drv(구동 방식 : 사륜(4), 전륜(f), 후륜(r) 변수에 채우기(누적 막대 그래프)
qplot(hwy, data=mpg, fill=drv) # fill 옵션 적용fill : 막대 그래프 상에서 색상으로 구별하여 시각화 - 변수에 대한 특징이 가시적으로 확인 가능
연비에 따른 구동방식의 분포도
분석 결과 : 4륜 - 연비가 좋지 못함, 전륜 - 연비가 좋음 , 후륜 - 개체가 많지 않음
③ binwidth 속성 : 막대 폭 지정 옵션
qplot(hwy, data = mpg, fill = drv, binwidth=2)binwidth : 막대의 폭 크기 지정
④ facets 속성 : drv 변수 값으로 컬럼단위와 행단위로 패널 생성(분리)
- 열 단위로 패널 생성
qplot(hwy, data = mpg, fill = drv, facets = .~drv , binwidth=2)
- 행 단위로 패널 생성
qplot(hwy, data = mpg, fill = drv, facets = drv~. , binwidth=2)
⑤ - 1 두 개 변수 대상 qplot() 함수 적용
qplot( x축 , y축 , data)
qplot(displ, hwy, data=mpg)mpg 데이터 셋의 displ 과 hwy 변수 이용 (산점도)
⑤ - 2 두 개 변수 대상 qplot() 함수 적용
- displ, hwy 대상으로 drv 변수값으로 생상 적용 산점도 그래프
qplot(displ, hwy, data=mpg, color = drv)
⑤ - 3 두 개 변수 대상 qplot() 함수 적용
- displ 과 hwy 변수와 관계를 drv로 구분
qplot(displ, hwy, data=mpg, color = drv, facets = .~drv)
3) 미적 요소 맵핑(mapping) : qplot() 함수 제공하는 색상, 크기, 모양
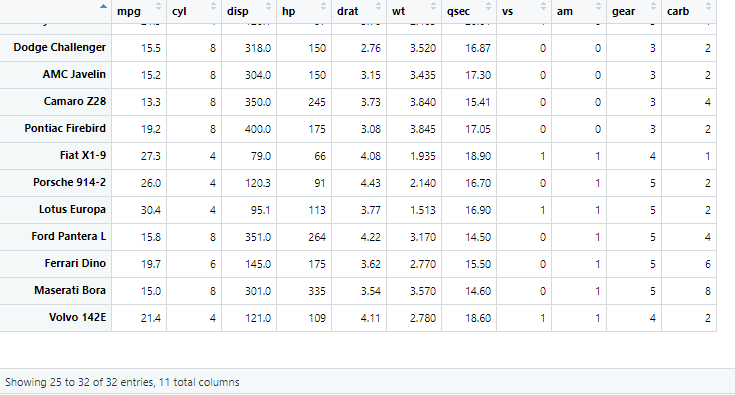
mtcars
더보기
mtcars 데이터 셋
주요 변수: mpg(연비)
cyl(실린더 수)
displ(엔진 크기)
hp(마력)
wt(중량)
gear(앞쪽 기어 수)
carb(카뷰레터 수)
qsec(1사분위의 거리(마일)까지 주행 시간)
mtcars 을 활용하여 특징을 살펴보겠습니다.
- wt(무게), mpg(연비) 그래프 그리기
qplot(wt,mpg, data=mtcars)
- wt(무게), mpg(연비) 그래프 그리기 + color(색상)
qplot(wt,mpg, data=mtcars, color=factor(carb)) # 색상 적용
색상 + carb(카뷰레터 수) 특징 시각화
- wt(무게), mpg(연비) 그래프 그리기 + size(크기)
qplot(wt,mpg, data=mtcars, color=factor(carb), size=qsec) # 크기 적용
크기 + qsec(1사분위의 거리(마일)까지 주행 시간) 특징 시각화
※ 거리는 일정한데 시간이 많이 걸리면 연비가 좋지 않음.
- wt(무게), mpg(연비) 그래프 그리기 + shape(모양)
qplot(wt,mpg, data=mtcars, color=factor(carb), size=qsec, shape=factor(cyl))
모양 + cyl(실린더 수) 특징 시각화
4) 기하학적 객체 적용
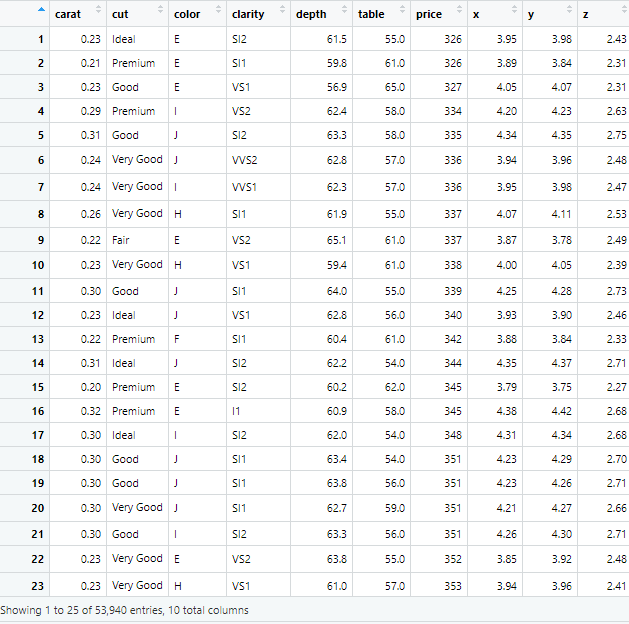
diamonds
더보기
diamonds 데이터 셋
주요 변수
price : 다이아몬드 가격($326 ~ $18,823)
diamonds 활용하여 특징을 살펴보겠습니다.
ⓘ geom = "bar" (속성으로 막대그래프 그리기)
clarity 빈도수 막대 그래프 + fill=cut, geom = "bar" (색 채우기)
qplot(clarity, data=diamonds, fill=cut, geom = "bar") # 레이아웃에 색 채우기
clarity 빈도수 막대 그래프 + color =cut, geom = "bar" (테두리 적용)
qplot(clarity, data=diamonds, color=cut, geom = "bar")
② geom = "point" (산점도)
cyl 변수의 요인으로 point 크기 적용
qplot(wt,mpg, data=mtcars, color=factor(carb), geom = "point")
cyl 변수의 요인으로 point 크기 적용, carb변수의 요인으로 포인트 색 적용
qplot(wt,mpg, data=mtcars, color=factor(carb), size=factor(cyl), geom = "point")
qesc 변수로 포인트 크기 적용, cyl 변수의 요인으로 point 적용
qplot(wt,mpg,data=mtcars, size=qsec, color=factor(carb), shape=factor(cyl),geom = "point")
③ geom = "smooth" (분포도에 대한 평균치)
분포도 출력
qplot(wt,mpg,data=mtcars,geom = "smooth")
기하학의 2가지 사용(smooth + point)
qplot(wt,mpg,data=mtcars,geom = c("point", "smooth"))
cyl 변수의 요인으로 point, smooth 크기 적용
qplot(wt,mpg,data=mtcars,color=factor(cyl), geom = c("point", "smooth"))
④ geom = "line" (선으로 순차적인 분포도)
qplot(wt,mpg,data=mtcars,geom = "line")
기하학의 2가지 사용(point + line)
qplot(wt,mpg,data=mtcars,color=factor(cyl), geom = c("point","line"))
⑤ geom="freqpoly"
5) ggplot() 함수
단계 1(layer1) : 배경 설정하기
ggplot(data=mpg, aes(x=displ, y=hwy)) #aesthetics(미학)# aesthetics(미학)
단계 2(layer 2): 그래프 추가하기
ggplot(data=mpg, aes(x=displ, y=hwy)) + geom_point()
x축 0~7 / y축 0~40 <default>
단계 3(layer 3) : 축범위 조정하는 설정 추가하기(축에 대한 가변적 설정)
ggplot(data=mpg, aes(x=displ, y=hwy)) + geom_point() + xlim(3,6) + ylim(10,30)
xlim() : x축의 범위 설정 ylim() : y축의 범위 설정
● 미적 요소 맵핑
aes(x, y, color)
p <- ggplot(diamonds, aes(carat,price,color=cut)) # (x= , y=) 생략 가능
p + geom_point()
● ① 기하학적 객체(geometric object:점/선/막대) 적용
p <- ggplot(mtcars, aes(mpg,wt,color=factor(cyl)))
p + geom_line()
● ② 기하학적 객체(geometric object:점/선/막대) 적용
p <- ggplot(mtcars, aes(mpg,wt,color=factor(cyl)))
p + geom_point()
● ① 미적 요소 맵핑과 기하학적 객체 적용
stat_bin() : (aes():미적요소) + ('geom=')) : 기하적 요소 + 기능 동시 적용
p <- ggplot(diamonds, aes(price))
p + stat_bin(aes(fill=cut), geom = 'bar')
● ② 미적 요소 맵핑과 기하학적 객체 적용
p <- ggplot(diamonds, aes(price))
p + stat_bin(aes(fill=cut), geom = "area")
● ③ 미적 요소 맵핑과 기하학적 객체 적용
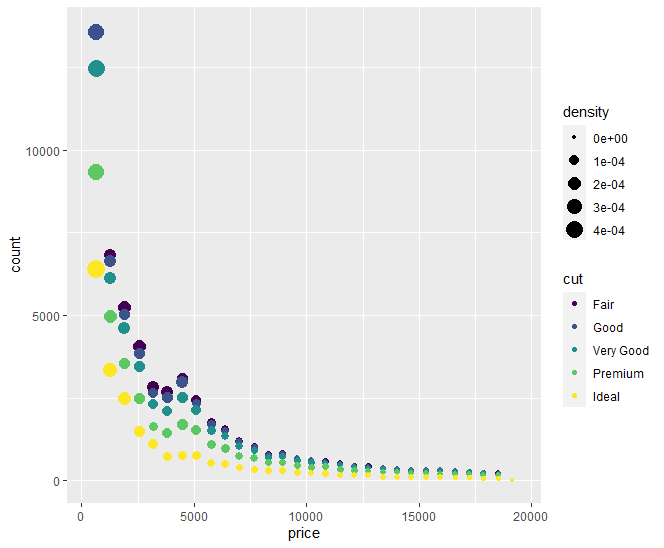
p <- ggplot(diamonds, aes(price))
p + stat_bin(aes(color=cut, size = ..density..),geom = "point")
● 테마(Thema) 적용
p <- ggplot(diamonds, aes(carat,price, color=cut))
p <- p + geom_point() + ggtitle("다이아몬드 무게와 가격의 상관관계")
p
● ① 테마(Thema) 적용 + 추가
p + theme(title=element_text(color = "blue", size =25))
● ② 테마(Thema) 적용 + 추가
p + theme(
title=element_text(color = "blue", size =25), # 축제목
axis.title = element_text(size = 14,face = "bold"), # 축제목
axis.title.x=element_text(color = "green"), # x축제목
axis.title.y=element_text(color = "red")) # y축제목
● ③ 테마(Thema) 적용 + 추가
p + theme(
title=element_text(color = "blue", size =25), # 축제목
axis.title = element_text(size = 14,face = "bold"), # 축제목
axis.title.x=element_text(color = "green"), # x축제목
axis.title.y=element_text(color = "red"), # y축제목
axis.text=element_text(size = "14"), # 축이름(0~5)
axis.text.x=element_text(color="orange"), # x축이름(0~5)
axis.text.y=element_text(color="yellow"), # y축이름(0~5)
legend.title = element_text(size = 20, face = "bold", color = "red"), # 범례 세팅
legend.position = "bottom",
legend.direction = "horizontal" # 수평형태로 재배치
)
6) ggsave()
p <- ggplot(diamonds, aes(carat, price, color=cut))
p + geom_point()
- 가장 최근 그래프 저장
ggsave(file="C:/workspaces/R/output/diamond_price.pdf")
ggsave(file="C:/workspaces/R/output/diamond_price.jpg", dpi = 72)
ggsave(file="C:/workspaces/R/output/diamond_price.png",plot = p, width = 10, height = 5)
7) 지도 공간 기법 시각화
stamen Maps API 이용 - 지도 관련 패키지 설치
library(ggplot2)
install.packages("ggmap")
library(ggmap)
● 위도와 경도 중심으로 지도 시각화
seoul <- c(left=126.77, bottom = 37.40, right = 127.17, top = 37.70)
map <- get_stamenmap(seoul, zoom = 12, maptype = 'terrain')
ggmap(map)