등간척도와 비율척도의 차이는 절대 원점(0)의 의미 입니다. - 등간척도는 절대원점(0)을 가지고 있지 않음(의미 없음) - 비율척도는 절대원점(0)을 가지고 있는 척도(0을 기준으로 한 수치)
생황비(cost) 변수 대상 요약 통계량 구하기
length(data$cost) # 297 (레코드 개수)
summary(data$cost) # 요약통계량 - 의미 있음(mean) / Mean = 8.784 , Median = 5.4
- 출력값 -
Min. 1st Qu. Median Mean 3rd Qu. Max. NA's
-457.200 4.400 5.400 8.784 6.300 675.000 30
plot(data$cost) # 분포도 확인
데이터 정제(이상치 제거)
data <- subset(data, data$cost>=2 & data$cost <= 10) # 총점기준
plot(data$cost)
x <- data$cost
mean(x) 출력값 : 5.354032
평균이 극단치에 영향을 받는 경우 = 중위수(median) 대체
median(x) 출력값 : 5.4
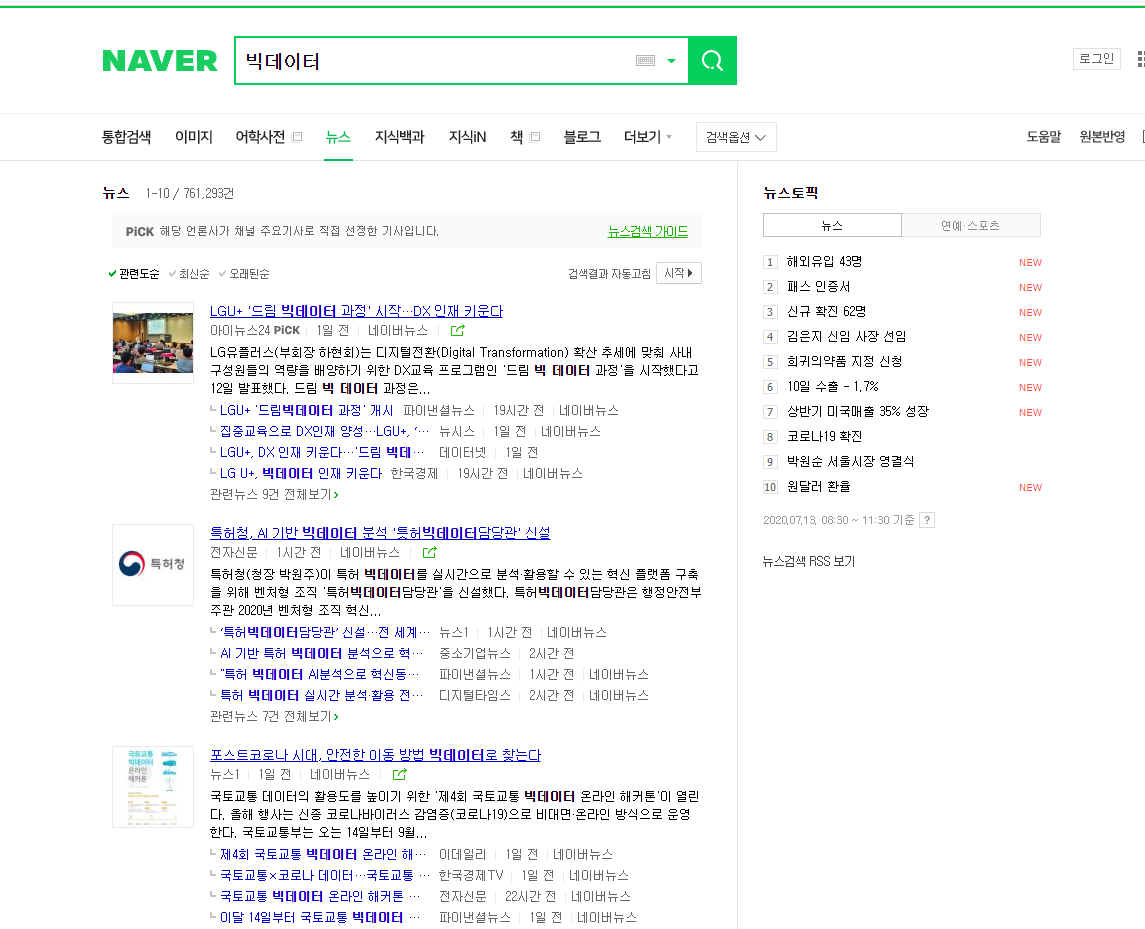
크롤링(crawling) 혹은 스크래핑(scraping)은웹 페이지를 그대로 가져와서 거기서 데이터를 추출해 내는 행위로, 크롤링하는 소프트웨어는크롤러(crawler)라고 부릅니다.
무수히 많은 컴퓨터에 분산 저장되어 있는 문서를 수집하여 검색 대상의 색인으로 포함시키는 기술. 어느 부류의 기술을 얼마나 빨리 검색 대상에 포함시키냐 하는 것이 우위를 결정하는 요소로서 최근 웹 검색의 중요성에 따라 발전되고 있습니다.
관련 용어
(1) 웹크롤링(web crawling)
- 웹을 탐색하는 컴퓨터 프로그램(크롤러)를 이용하여 여러 인터넷 사이트의 웹 페이지 자료를 수집해서 분류하는 과정. - 또한 크롤러(crawler)란 자동화된 방법으로 월드와일드웹(www)을 탐색하는 컴퓨터 프로그램을 의미.
(2) 스크래핑(scarping)
- 웹사이트의 내용을 가져와 원하는 형태로 가공하는 기술 - 즉 웹사이트의 데이터를 수집하는 모든 작업을 의미 - 결국, 크롤링도 스크래핑 기술의 일종 - 크롤링과 스크래핑을 구분하는 것은 큰 의미가 없음
(3) 파싱(parsing)
- 어떤 페이지(문서, HTML등) 에서 시용자가 원하는 데이터를 특정 패턴이나 순서로 추출하여 정보를 가공하는 것. - 예를들면 HTML 소스를 문자열로 수집한 후 실제 HTML태그로 인식할 수 있도록 문자열을 의미있는 단위로 분해하고, 계층적인 트리 구조를 만드는 과정.
(1) 패키지 설치 및 준비
install.packages("tidyverse")
install.packages("rvest") # html 추출
library(tidyverse)
library(rvest)
base_url <- "https://search.naver.com/search.naver?
&where=news&query=%EB%B9%85%EB%8D%B0%EC%9D%B4%ED%84%B0&sm=tab_pge&
sort=0&photo=0&field=0&reporter_article=&pd=0&ds=&de=&docid=&nso=so:r,p:all,a:all&
mynews=0&cluster_rank=55&refresh_start=0&start="
# url의 순서는 중요하지 않고, 내용에 무엇이 담겨있는지가 중요.
# &start=1 값을 뒤로 보내고 1 값을 지움
# 1페이지 1, 2페이지 11, 3페이지 21 ...
- url 가져오기
urls <- NULL
for(x in 0:9){ #0~9까지 10개의 순차적인 값 출력(10번 반복)
urls <- c(urls, paste(base_url,x*10+1,sep= ''))
}
urls
- 통계적 가설 검정은통계적 추측의 하나로서, 모집단 실제의 값이 얼마가 된다는 주장과 관련해, 표본의 정보를 사용해서 가설의 합당성 여부를 판정하는 과정을 의미합니다. 간단히가설 검정이라고 부르는 경우가 많습니다.
- 가설(Hypothesis)의 설정 : 가설은 검정하고자 하는 모집단의 모수(조사하고자 하는 자료의 평균, 분산, 표준편차, 상관계수)에 대하여 항상 다음의 둘로 설정 합니다.
1. 귀무가설 :[영(0)가설:null hypothesis] Ho : 두 모수(예: 두 평균)에 대한 값이 같다고 놓을때, 기각(reject) 또는 채택(accept)하려고 세운 검정의 대상이 되는 가설이며 H0로 나타냅니다. 귀무(영)가설은 수식 표현대로 “두 모수는 같다”와 같이 설정하는 것입니다.
- 효과가 없다라는 가정에서 시작(변수간에 관계, 차이 없음)
2. 연구가설 : [연구가설:alternative hypothesis]H1: 귀무(영)가설이 채택되지 않을 때, 즉 두 모수에 대한 값이 다를 때 가설입니다. 여기에는 다음과 같이구분하는 두 가지 검정방법이 존재한다
① 양측검정 : 두 모수는 같지 않다.
② 단측 검증 : 두 모수중 하나는 다른 것 보다 크다 또는 작다.
효과가 있다라는 가정에서 시작(변수간에 관계, 차이 존재)
- 주장하고 싶은 바 : 연구가설 , 반대 개념을 : 귀무가설 사용
설정한 기준에 의해서 채택하고 싶은 기준을 유의 수준의 값을 통해서 결정합니다. .
※ 논문에서 연구가설 제시, 귀무가설을 통해서 가설 검정
먼저 연구 가설 내용을통계적 가설로 바꾸어 줌으로써가설 검정(hypothesis test)이 시작됩니다.
H1 = „싞약A는 A암 치료에 효과가 있다.‟ H0 = „싞약A는 A암 치료에 효과가 없다.‟
석결과 : 생쥐 100마리를 대상으로 신약A를 투약한 결과 검정통계량의 유의확률(P=0.03)이 나왔습니다. – 이때 귀무가설은 기각되는가?
사회과학분야 임계값 : α=0.05(p<0.05(5%미만)) 적어도 96마리 이상 효과
의.생명분야 임계값 : α=0.01(99% 싞뢰도 보장) 적어도 99마리 이상 효과
2. 유의수준 결정
유의수준(Significant level)
- 1종 오류를 범할 수 있는 최대 호용 한계입니다.
1) 1종 오류 : 귀무가설이 참인데 기각한 경우
2) 2종 오류 : 귀무가설이 거짓인데 기각하지 않은 경우
통계학적으로 유의수준은 보통 0.05, 0.01, 0.001중 하나 (5%, 1,%, 0.1%)를 채택합니다.
귀무가설이 참이라고 가정했을 때 내가 구한 자료가 맞을 가능성이 유의수준 이하라면, 그 귀무가설은 기각하고 대립가설을 채택합니다.
가설 채택 또는 기각 기준 / 분석 결과 유의수준 이내 -> 가설 채택(그렇지 않으면 기각)
일반 사회과학분야 : α=0.05(p<0.05 ) / 95%
의생명분야 : 0.01 / 99%(1% 오차 허용, 99% 신뢰도 확보)
유의확률(p) : 귀무가설이 참인데도 불구하고 이를 기각할 확률 (잘못된 의사결정을 할 확률)
유의수준이 0.05라 할때, p가 0.05보다 적게 나와야 귀무가설을 기각하고 대립가설을 채택할 수 있습니다.
즉, 가설검정을 할 때 p값과 유의수준을 비교하여 귀무가설과 대립가설 둘 중 하나를 채택합니다.
3. 측정도구 선정
- 가설에 나오는 변수를 무엇으로 측정할 것인가를 결정하는 단계 - 가설에 나오는 변수(변인) 추출 - 변수의 척도를 고려 측정도구 선정
4. 데이터 수집(설문지, 웹, SNS)
데이터 수집이란?
계측기를 통해 들어오는 측정 자료들을컴퓨터를 이용하여 처리하고 결과를 얻어내는 것. 중앙에 연결된 컴퓨터와 원격지의단말기를 통해 자료를 수집하고 처리하는 것을 말하기도 하며 크게 외부의 센서(sensor)에 의해 자료를 모으는 것을 말합니다.
+)
– 선정된 측정도구를 이용하여 설문 문항 작성 단계 – 조사응답자 대상 설문 실시 & 회수 – 정형/비정형 데이터 수집(DB, WEB, SNS 등) – 본 단계까지 완료된 경우 - 연구목적과 배경, 연구모형, 연구가설까지 끝난 상태 = 논문 50% 이상 완성
5. 데이터 코딩/ 프로그래밍
- 코딩과 프로그래밍의 차이
코디은 프로그래밍과 같은 뜻으로 널리 사용됩니다. 하지만 좀더 구체적으로 살펴보면, 코딩은 명령을 컴퓨터가 이해할 수 있는 C언어, 자바, 파이선 등의 프로그래밍 언어로 입력하는 과정을 뜻하고 프로그래밍은 프로그래밍 언어를 사용해 프로그램을 만드는 일을 뜻합니다.
– 통계분석 프로그램(Excel, R, SPSS, SAS,) 데이터 입력 – 데이터 전처리(미 응답자, 잘못된 데이터 처리)
6. 통계분석 수행 (R,SPSS, SAS)
- 전문 통계분석 프로그램(R, SPSS, SAS) 분석 단계
- 통계 분석 기법
1) 빈도 분석
: 측정하여 얻은 데이터가 사람 수, 횟수 등의 빈도인 경우에 사용합니다.이 방법은 집단 간 빈도 차를 비교합니다.
2) 평균 분석
: 측정하여 얻은 데이터가 점수고 비교해야할 집단이두 개만 존재할 때, 두 개 집단의 평균 등을 비교하여 가설을
검증합니다.
3) 변량분석
: 측정하여 얻은 데이터가 점수고, 3개 이상 집단을 비교할 때 사용합니다.가장 많이 사용되는 검증 방법으로써,
영어로 ANOVA(analysis of variance)로 표현합니다.
4) 상관분석
: 두 변수간 관계성이 얼마나 큰가를 분석할 때 사용합니다. 상관분석에서는 변수들 간 상관성 유무만 확인하고,
인과관계는 분석하지 않습니다. 상관분석의 핵심은 상관계수(r)를 구하는 것입니다.
5) 회귀분석
: 독립변수가 종속변수에 영향을 미치는지 분석할 때 사용합니다. 회귀분석은 인과관계를 분석합니다.
관측된 사건들을 정량화해서 여러 독립변수와 종속변수의 관계를 함수식으로 설명합니다.
- 통계분석 방법을 계획하지 않고 데이터를 수집할 경우 실패 확률 높음
7. 결과분석 (논문/ 보고서)
– 연구목적과 연구가설에 대핚 분석 및 검증 단계 – 인구통계학적 특성 반영 – 주요 변인에 대한 기술통계량 제시 – 연구가설에 대한 통계량 검정 및 해석 – 연구자 의견 기술(논문/보고서 작성)
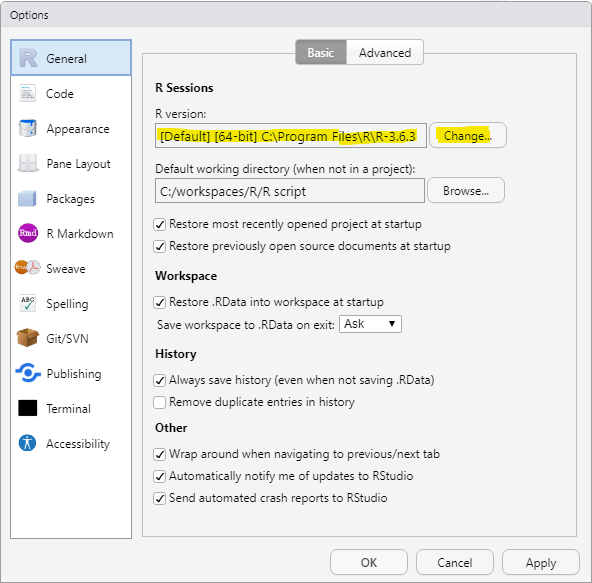
install.packages("KoKLP") # package ‘KoKNP’ is not available (for R version 4.0.1)
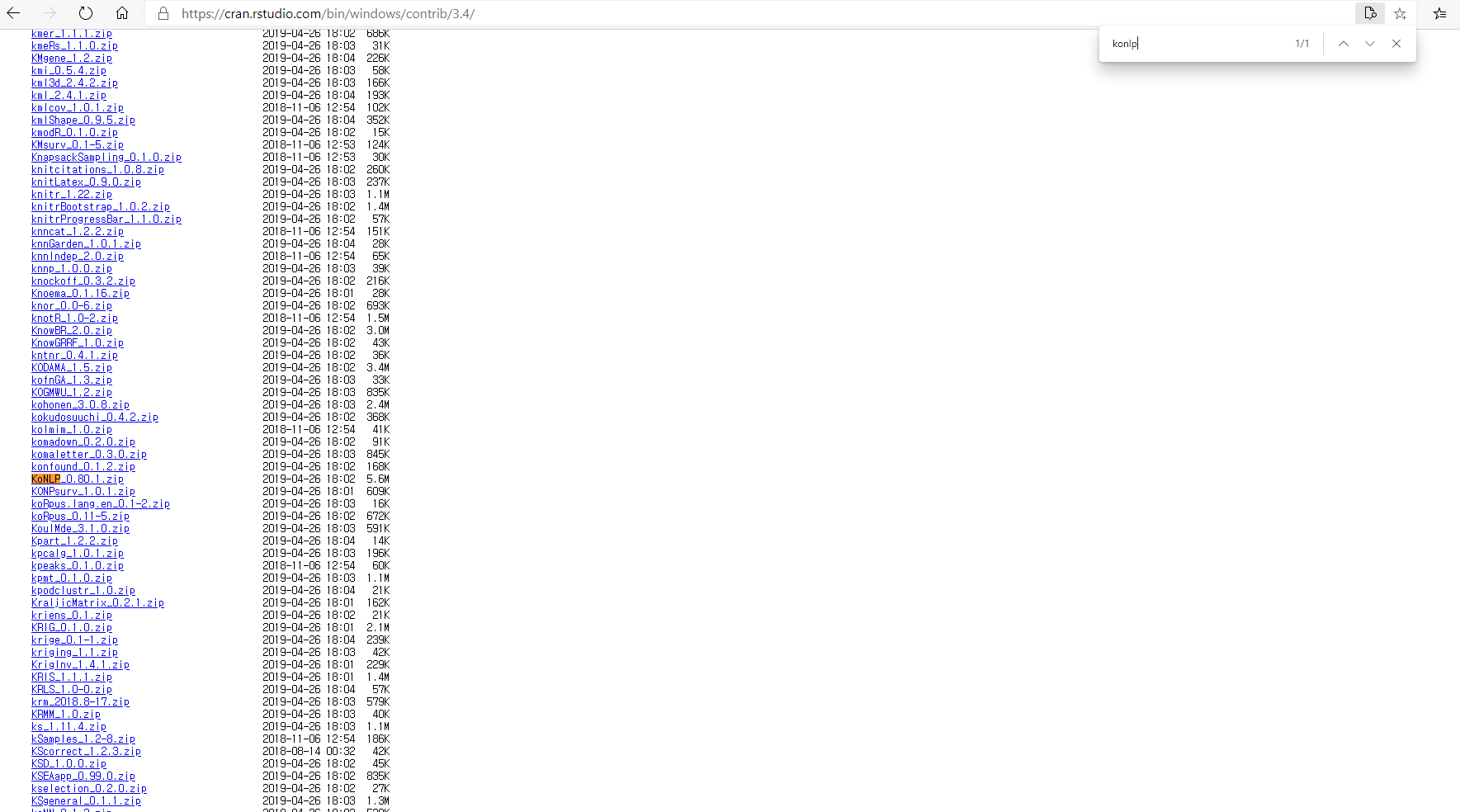
install.packages("https://cran.rstudio.com/bin/windows/contrib/3.4/KoNLP_0.80.1.zip",repos = NULL)
# repos = NULL : 버전은 다운한 3.6버전에 설치한다든 옵션
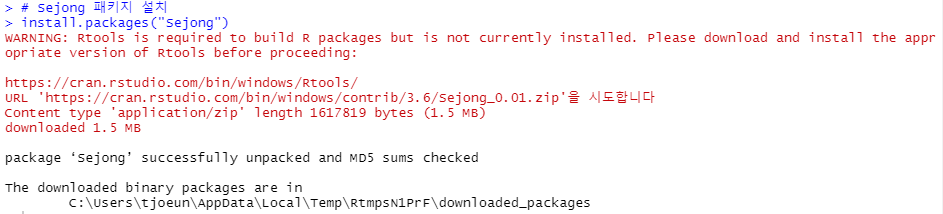
# Sejong 설치 : KoNLP 와 의존성 있는 현재 버전의 한글 사전
# Sejong 패키지 설치
install.packages("Sejong")
install.packages(c("hash","tau","RSQLite","rJava","devtools"))
library(Sejong)
library(hash)
library(tau)
library(RSQLite)
Sys.setenv(JAVA_HOME='C:/Program Files/Java/jre1.8.0_221')
library(rJava) # rJava를 올리기 전에 java의 위치를 지정해줘햔다.
library(devtools)
library(KoNLP)
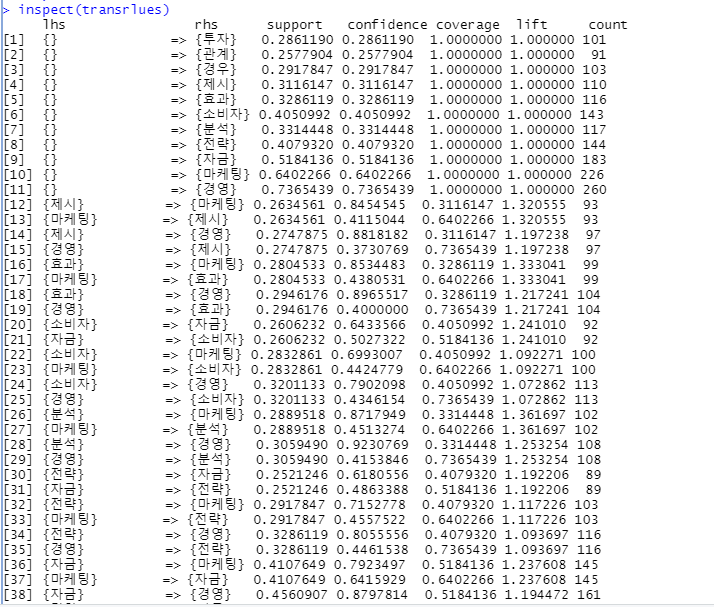
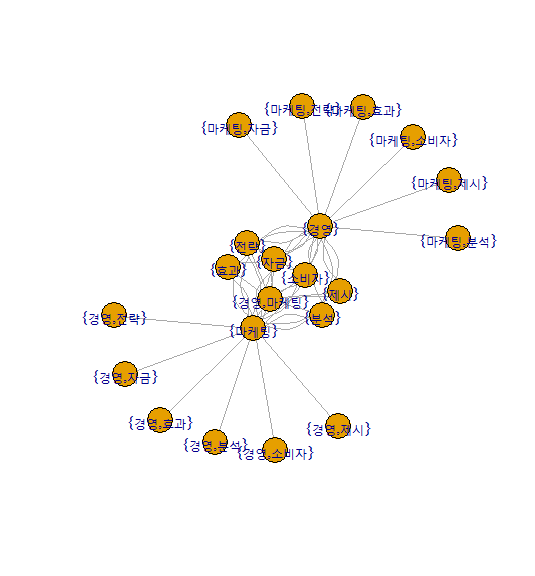
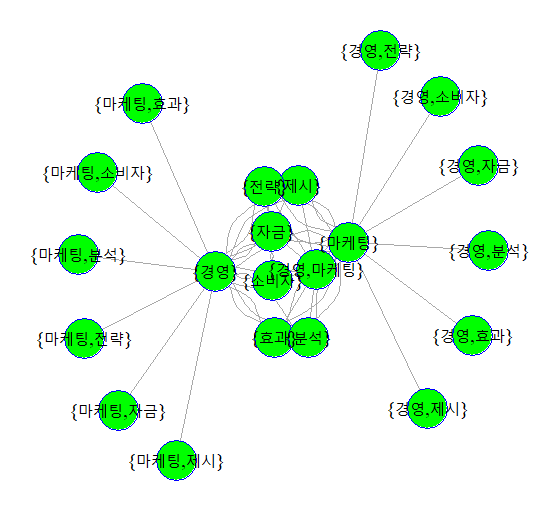
apriori() : 연관분석 기능 적용(규칙성을 찾음) , 자료구조의 형태는 transaction 일때 정상적으로 실행
support = 지지도 : 수치형의 값(상관도) = 퍼센트 값으로 최대값 1, 최소값 0 전체 거래에서 특정 물품 A와 B가 동시에 거래되는 비중으로,해당 규칙이 얼마나 의미가 있는 규칙인지를 보여줍니다. 지지도 = P(A∩B) : A와 B가 동시에 일어난 횟수 / 전체 거래 횟수
conf = 신뢰도 A를 포함하는 거래 중 A와 B가 동시에 거래되는 비중으로, A라는 사건이 발생했을 때 B가 발생할 확률이 얼마나 높은지를 말해줍니다. 신뢰도 = P(A∩B) / P(A) : A와 B가 동시에 일어난 횟수 / A가 일어난 횟수
buildDictionary (ext_dic = '저장할 사전 이름', user_dic = 변수 이름 )
3. 단어 추출 위한 사용자 정의 함수
- R 제공 함수로 단어 추출하기 - Sejong 사전에 등록된 신규 단어 테스트
paste(extractNoun("홍길동은 얼죽아를 최애로 생각하는, 빅데이터에 최대 관심을 가지고 있으면서,
페이스북이나 소셜네트워크로부터 생성 수집되어진 빅데이터 분석에 많은 관심을
가지고 있어요."),collapse=" ")
출력값:
[1] "홍길동은 얼죽아 최애로 생각 빅데이터에 최대 관심 페이스북
소셜네트워크 생성 수집 빅데이터 분석 관심"
paste( ) : 나열된 원소 사이에 공백을 두고 결과값을 출력 extractNoun( ) : 명사를 추출 collapse=" " : 찾은 단어 사이 ( )넣기
4. 단어 추출을 위한 사용자 정의 함수 정의하기
(1) 사용자 정의 함수 작성
[문자형 변환] -> [명사 단어 추출] -> [" "으로 데이터 연결하여 하나의 문자열로 출력]
Corpus() : 단어 처리의 단위 VectorSource() : vector 형으로 변환
② 데이터 전처리
myCorpusPrepro <- tm_map(myCorpus,removePunctuation) # 문장부호 제거
# - myCorpus 안에 들어있는 문장 부호를 삭제 한다.
myCorpusPrepro <-tm_map(myCorpusPrepro, removeNumbers) # 수치 제거
# - myCorpusPrepro 안에 들어있는 숫자 삭제 한다.
myCorpusPrepro <-tm_map(myCorpusPrepro, tolower) #영문자 소문자 변경
# - myCorpusPrepro 안에 들어있는 영문자 소문자 변경.
myCorpusPrepro <-tm_map(myCorpusPrepro, removeWords,stopwords('english'))
# 불용어(for, very, and, of, are...)제거
tm_map() : Corpus로 처리된 데이터를 받아서 필터링을 해준다. removePunctuation() : 문장부호 삭제 removeNumbers() : 수치 제거 tolower() : 영문자 소문자 변경 removeWords , stopwords('english') : 불용어(for, very, and, of, are...)제거
③ 전처리 결과 확인
inspect(myCorpusPrepro[1])
6. 단어 선별
- 단어 2음절 ~ 8음절 사이 단어 선택하기
- Corpus 객체를 대상으로 TermDocumentMatrix() 함수를 이용하여 분석에 필용한 단어 선별하고 단어/문서 행렬을
wordResult <- sort(rowSums(myTerm_df), decreasing = T)
wordResult[1:10]
- 출력값 -
데이터 분석 빅데이터 처리 사용 수집 시스템 저장 결과 노드
91 41 33 31 29 27 23 16 14 13
빈도수로 내림차순 정렬 decreasing = T : 내림차순 정렬
사용이 빅데이터와 관련 없는 단어가 출력될 수 있습니다.
8. 불필요한 용어 제거 시작
① 데이터 전처리
myCorpusPrepro <- tm_map(myCorpus,removePunctuation) # 문장부호 제거
# - myCorpus 안에 들어있는 문장 부호를 삭제 한다.
myCorpusPrepro <-tm_map(myCorpusPrepro, removeNumbers) # 수치 제거
# - myCorpusPrepro 안에 들어있는 숫자 삭제 한다.
myCorpusPrepro <-tm_map(myCorpusPrepro, tolower) #영문자 소문자 변경
# - myCorpusPrepro 안에 들어있는 영문자 소문자 변경.
myCorpusPrepro <-tm_map(myCorpusPrepro, removeWords,stopwords('english'))
# 불용어(for, very, and, of, are...)제거
myStopwords <- c(stopwords('english'),"사용","하기")
myCorpusPrepro <-tm_map(myCorpusPrepro, removeWords,myStopwords) # 불용어 제거
inspect(myCorpusPrepro[1:5]) # 데이터 전처리 결과 확인
② 단어 선별 - 단어 길이 2 ~ 8 개 이상 단어 선별.
myCorpusPrepro_term <- TermDocumentMatrix(myCorpusPrepro,control=list(wordLengths=c(4,16)))
myTerm_df <- as.data.frame(as.matrix(myCorpusPrepro_term))
dim(myTerm_df) # 출력값 : [1] 696 76
wordResult <- sort(rowSums(myTerm_df), decreasing = T)
wordResult[1:10]
- 출력값 -
데이터 분석 빅데이터 처리 수집 시스템 저장 결과 노드 얘기
91 41 33 31 27 23 16 14 13 13
9. 단어 구름(wordcloud) 시각화
디자인 적용전
myName <- names(wordResult) # 단어 이름 축출
wordcloud(myName, wordResult) # 단어 구름 시각화
pal <- brewer.pal(12,"Paired") # 12가지 생상 pal
windowsFonts(malgun=windowsFont("맑은 고딕"))
brewer.pal(색상의 수)
3) 단어 구름 시각화
x11() # 별도의 창을 띄우는 함수
wordcloud(word.df$word, word.df$freq, scale = c(5,1), min.freq = 3, random.order = F,
rot.per = .1, colors = pal, famliy = "malgun")
random.order = F : 가장 큰 크기를 가운데 고정
txt <- readLines("C:/workspaces/R/data/hiphop.txt")
head(txt)
- 출력값 -
[1] "\"보고 싶다" "이렇게 말하니까 더 보고 싶다" "너희 사진을 보고 있어도"
[4] "보고 싶다" "너무 야속한 시간" "나는 우리가 밉다"
② 특수문자 제거
txt1 <- str_replace_all(txt, "\\W", " ")
head(txt1)
- 출력값 -
[1] " 보고 싶다" "이렇게 말하니까 더 보고 싶다" "너희 사진을 보고 있어도"
[4] "보고 싶다" "너무 야속한 시간" "나는 우리가 밉다"
wordcount <- table(unlist(nouns)) # unlist( ) : list -> vector
head(wordcount);tail(wordcount) # 상위 6개 출력 ; 하위 6개 출력
- 출력값 -
1 100 168 17
12 2 8 3 1 1
히 히트 힘 힘겹 힘내잔 힙합
8 1 10 1 1 1
⑤ 데이터 프레임으로 변환
df_word<-as.data.frame(wordcount,stringsAsFactors = F)
tail(df_word)
- 출력값 -
Var1 Freq
3078 히 8
3079 히트 1
3080 힘 10
3081 힘겹 1
3082 힘내잔 1
3083 힙합 1
stringsAsFactors = F : 문자열 그대로 형변환 없이 출력
stringsAsFactors = T : factor 형으로 출력
⑥ 변수명 수정
names(df_word) <- c('word', 'freq')
tail(df_word)
- 출력값 -
word freq
3078 히 8
3079 히트 1
3080 힘 10
3081 힘겹 1
3082 힘내잔 1
3083 힙합 1
⑦ 상위 20개 내림차순으로 추출
df_word <- filter(df_word,nchar(word) >= 2)
top_20 <- df_word %>% arrange(desc(freq)) %>% head(20) # 내림차순으로 정렬(가장 많이 언급된 단어)
top_20
- 출력값 -
word freq
1 you 89
2 my 86
3 YAH 80
4 on 76
5 하나 75
6 오늘 51
7 and 49
8 사랑 49
9 like 48
10 우리 48
11 the 43
12 시간 39
13 love 38
14 to 38
15 we 36
16 it 33
17 em 32
18 not 32
19 역사 31
20 flex 30