: 경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구로인공지능의 한 분야로 간주합니다. 또한 컴퓨터가 학습할 수 있도록 하는알고리즘과 기술을 개발하는 분야입니다. 가령, 기계 학습을 통해서 수신한이메일이스팸인지 아닌지를 구분할 수 있도록 훈련할 수 있습니다.
- 머신러닝 에서의 일반화는훈련이후 새롭게 들어온 데이터를 정확히 처리할 수 있는 능력을 말하기도 합니다.
알고리즘의 유형
① 지도 학습(Supervised Learning)
: 사람이교사로서 각각의 입력(x)에 대해 레이블(y)을 달아놓은 데이터를 컴퓨터에 주면 컴퓨터가 그것을 학습하는 것 입니다. 사람이 직접 개입하므로 정확도가 높은 데이터를 사용할 수 있다는 장점이 있지만, 대신에 사람이 직접 레이블을 달아야 하므로 인건비 문제가 있습니다. 따라서 구할 수 있는 데이터양도 적다는 문제가 있습니다.
– 인간 개입에 의한 분석 방법 – 종속변수(y) 존재 : 입력 데이터에 정답 포함 – 분석방법 : 가설검정(확률/통계) → 인문.사회.심리 계열(300년) – 분석유형 : 회귀분석, 분류분석, 시계열 분석 → 추론통계 기반(모집단에 대한 결과 분석)
- 분류(Classification)
: 레이블 y가이산적(Discrete)인 경우 즉, y가 가질 수 있는 값이 [0,1,2 ..]와 같이 유한한 경우 분류, 혹은 인식 문제라고 합니다 일상에서 가장 접하기 쉬우며, 연구가 많이 되어있고, 기업들이 가장 관심을 가지는 문제 중 하나 입니다. 이런 문제들을 해결하기 위한 대표적인 기법들로는 로지스틱 회귀법, KNN, 서포트 벡터 머신 (SVM), 의사 결정 트리 등이 있습니다.
- 분류분석 : 고객 이탈분석(번호이동, 반응고객 대상 정보 제공)
- 회귀(Regression)
: 레이블 y가 실수인 경우 회귀문제라고 부릅니다. 데이터들을 쭉 뿌려놓고 이것을 가장 잘 설명하는 직선 하나 혹은 이차함수 곡선 하나를 그리고 싶을 때 회귀기능을 사용합니다. 잘 생각해보면 데이터는 입력(x)와 실수 레이블(y)의 짝으로 이루어져있고, 새로운 임의의 입력(x)에 대해 y를 맞추는 것이 바로 직선 혹은 곡선이므로 기계학습 문제입니다. 통계학의 회귀분석 기법 중 선형회귀 기법이 이에 해당하는 대표적인 예입니다.
- 회귀분석 : 인과관계 예측(회귀분석 - p값 제공)
② 비지도 학습(Unsupervised Learning)
:사람 없이 컴퓨터가 스스로 레이블 되어 있지 않은 데이터에 대해 학습하는 것으로 y없이 x만 이용해서 학습하는 것 입니다. 정답이 없는 문제를 푸는 것이므로 학습이 맞게 됐는지 확인할 길은 없지만, 인터넷에 있는 거의 모든 데이터가 레이블이 없는 형태로 있으므로 앞으로 기계학습이 나아갈 방향으로 설정되어 있습니다. 통계학의 군집화와 분포 추정 등의 분야와 밀접한 관련이 있습니다 .
– 컴퓨터 기계학습에 의한 분석 방법 – 종속변수(y) 없음 : 입력 데이터에 정답 없음 – 분석방법 : 규칙(패턴분석) → 공학.자연과학 계열(100년) – 분석유형 : 연관분석, 군집분석 → 데이터마이닝 기반
- 군집화(Clustering)
: 데이터가 쭉 뿌려져 있을 때 레이블이 없다고 해도 데이터간 거리에 따라 대충 두 세개의 군집으로 이렇게 x만 가지고 군집을 학습하는 것을 군집화 라고 합니다.
- 군집분석 : 그룹화를 통한 예측(그룹 특성 차이 분석-고객집단 이해)
분포 추정(Underlying Probability Density Estimation)
: 군집화에서 더 나아가서, 데이터들이 쭉 뿌려져 있을 때 얘네들이 어떤 확률 분포에서 나온 샘플들인지 추정하는 문제를 분포 추정이라고 합니다.
지도 학습 vs 비지도 학습
분류
지도 학습
비지도 학습
주관
사람의 개입에 의한 학습
컴퓨터에 의한 기계학습
기법
확률과 통계 기반 추론 통계
패턴분석 기반 데이터 마이닝
유형
회귀분석, 분류분석(y변수 존재)
군집분석, 연관분석(y변수 없음)
분야
인문, 상회 계열
공학, 자연 계열
③ 준지도 학습(Semisupervised learning)
: 레이블이 있는 데이터와 없는 데이터 모두를 활용해서 학습하는 것인데, 대개의 경우는다수의 레이블 없는 데이터를 약간의 레이블 있는 데이터로 보충해서학습하는 종류의 문제를 다룬다.
④ 강화 학습(Reinforcement Learning)
: 강화학습은 현재의 상태(State)에서 어떤 행동(Action)을 취하는 것이 최적인지를 학습하는 것입니다.
확률론과 통계학에서 두 변수간에 어떤 선형적 관계를 갖고 있는 지를 분석하는 방법이다. 두변수는 서로 독립적인 관계로부터 서로 상관된 관계일 수 있으며, 이때 두 변수간의 관계의 강도를 상관관계(Correlation, Correlation coefficient)라 한다. 상관분석에서는 상관관계의 정도를 나타내는 단위로 모상관계수 ρ를 사용한다. 상관관계의 정도를 파악하는 상관계수(Correlation coefficient)는 두 변수간의 연관된 정도를 나타낼 뿐 인과관계를 설명하는 것은 아니다. 두 변수간에 원인과 결과의 인과관계가 있는지에 대한 것은 회귀분석을 통해 인과관계의 방향, 정도와 수학적 모델을 확인해 볼 수 있다.
상관 관계 분석 중요사항
– 회귀분석 전 변수 간 관련성 분석(가설 검정 전 수행) – 상관계수 -> 피어슨(Pearson) R계수 이용 관련성 유무
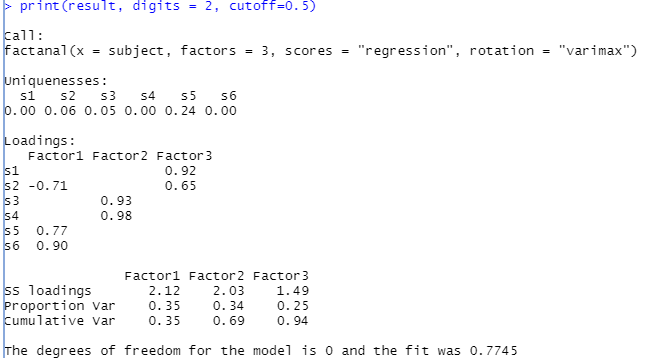
result <- factanal(subject, factors = 2, rotation = "varimax")
result # p-value is 0.0232 < 0.05 # 요인수가 부족.
유의 확률 값 = 0.0232 < 0.05 = 기각
결과 : 2개로 결합하는 것은 적합하지 않다. 많은 성분들이 손실한다.
② 고유값으로 가정한 3개 요인으로 분석
result <- factanal(subject, factors = 3, # 요인 개수 지정
rotation = "varimax", # 회전방법 지정("varimax", "promax", "none")
scores="regression") # 요인점수 계산 방법
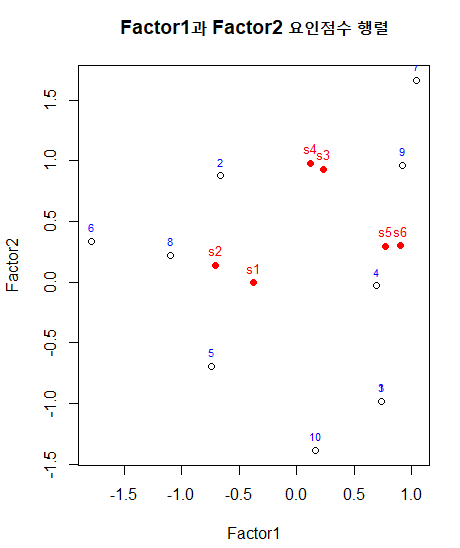
result
제품만족도 저장 데이터프레임
s <- data.frame(dw_df$Q8, dw_df$Q9, dw_df$Q10, dw_df$Q11)
제품친밀도 저장 데이터프레임
c <- data.frame(dw_df$Q1, dw_df$Q2, dw_df$Q3)
제품적절성 저장 데이터프레임
p <- data.frame(dw_df$Q5, dw_df$Q6, dw_df$Q7)
4) 분산 분석(세 집단 간 평균 차이 검정) , F 검정(분석), ANOVA 검정(분석)
result <- aov(score ~ method2, data = data2)
result -- 주의)검정에 필요한 값을 얻지 못합니다.
- 출력값 -
Call:
aov(formula = score ~ method2, data = data2)
Terms:
method2 Residuals
Sum of Squares 99.36805 96.90184
Deg. of Freedom 2 85
Residual standard error: 1.067718
Estimated effects may be unbalanced
names(result) - 컬럼의 이름 반환
- 출력값 -
[1] "coefficients" "residuals" "effects" "rank" "fitted.values" "assign"
[7] "qr" "df.residual" "contrasts" "xlevels" "call" "terms"
[13] "model"
summary(result)
aov(종속변수(y축) ~ 독립변수(x축) , data)
p-value=9.39e-14 < 0.05 귀무가설 기각
5)사후 검점
집단간 차이 상세보기 --> A!=B!=C, A==B!=C, A!=B==C
TukeyHSD(result)
교육방법 간 비교 --> p 값 tapply 차이 검정 ) --> 4.187097 6.800000 5.610000
6) 사후 검정 시각화
plot(TukeyHSD (result))
해석 ) A, B, C 집단간 모두 차이 존재
최종 결과 : 유의수준 0.05 에서 귀무가설이 기각되었다 . 따라서 교육방법에 따른 세 집단 간 실기시험의 평균에 차이가 있는 것으로 나타났다 . 또한 사후검정 방법인 Tukey 분석을 실시한 결과 '방법2 - 방법1’ 의 평균 점수의 차이가 가장 높은 것으로 나타났다.
x <- data$method # 교육방법(1:PT,2:Coding)
y <- data$survey # 만족도(1:만족, 0:불만족)
3단계 집단별 빈도분석
table(x)
table(y)
- 출력값 -
x
1 2
150 150
y
0 1
55 245
4단계 두 변수에 대한 교차분석
table(x, y, useNA = "ifany") # 결측치 존재시 display
- 출력값 -
y
x 0 1
1 40 110
2 15 135
-- 두 집단 비율 차이 검정 --
단계1. 양측 검정
prop.test(c(110,135), c(150,150)) # PT/Coding 교육 방법에 대한 비율 차이 검정.(만족도 넣음)
prop.test(c(110,135), c(150,150), alternative = "two.sided", conf.level = 0.95)
p-value = 0.0003422 => 귀무가설 기각.연구가설 채택
단계2. 방향성이 있는 단측가설 검정: PT > Coding
- alternative = "greater"
prop.test(c(110,135), c(150,150), alternative = "greater", conf.level = 0.95)
p-value = 0.9998 > 0.05(PT > Coding) -- 기각
- alternative = "less"
prop.test(c(110,135), c(150,150), alternative = "less", conf.level = 0.95)
p-value = 0.0001711 < 0.05(PT < Coding) 결론 : pt 만족도가 코딩 만족도 보다 떨어진다.
2. 두 집단 평균 검정(독립표본 T검정)
방법 : 두 집단간 평균 차이에 관한 분석
작업절차 1. 실습 파일 가져오기 2. 두 집단 subset 작성(데이터 정제 , 전처리) 3. 두 집단간 동질성 검증(정규 분포 검정) -> var.test()
4. 두 집단 평균 차이 검정
-> t.test() or wilcox.test()
분석절차
< 연구가설 >
- 연구가설(H1) : 교육방법에 따른 두 집단 간 실기시험의 평균에 차이가 있다. - 귀무가설(H0) : 교육방법에 따른 두 집단 간 실기시험의 평균에 차이가 없다.
<연구환경> IT 교육센터에서 PT를 이용한 프레젠테이션 교육방법과 실시간 코딩 교육 방법을 적용하여 1개월 동안 교육 받은 교육생 각 150명을 대상으로 실기시험을 실시 하였다. 두 집단간 실기시험의 평균에 차이가 있는가 검정한다.
결과 : 동질성을 가지고 있다. ( 0.3002 > 0.05 ) -> t.test() - ( T검정 사용)
- 두 집단 평균 차이 검정
단계1. 양측검정
t.test(a1, b1)
t.test(a1, b1, alternative = "two.sided", conf.level = 0.95)
결과 : p-value = 0.0411 < 0.05 - 교육방법 : 따른 두 집단간 실기시험의 평균에 차이가 있다.
단계2. 방향성을 갖는 단측가설 검정
- alternative = "greater"
t.test(a1, b1, alternative = "greater", conf.level = 0.95)
결과 : p-value = 0.9794 : a1을 기준으로 비교 -> a1이 b1보다 크지 않다 (기각)
- alternative = "less"
t.test(a1, b1, alternative = "less", conf.level = 0.95)
결과 : p-value = 0.02055 : a1을 기준으로 비교 -> a1이 b1보다 작다.
최종 결과 :
유의수준 0.05에서 귀무가설이 기각 되었다. 따라서 교육방법에 따른 두 집단간 실기시험의 평균에 차이가 있다 라고 말할 수 있다. 단측검정을 실시한 결과 교육 방법1이 교육방법 2보다 크지 않은 것으로 나타났다. 즉 실시간 코딩 교육 방법이 교육효과가 더 높은것 으로 분석 된다.
3. 대응 두 집단 평균 검정(대응 표본 T검정)
- 동일한 표본을 대상으로 측정된 두 변수의 평균 차이를 검정하는 분석방법. - 일반적으로 사전검사와 사후검사의 평균 차이를 검증할 때 많이 사용.
방법 : 대응 되는 두 집단간 평균 차이에 관한 분석
작업절차
1. 실습 파일 가져오기 2. 두 집단 subset 작성(데이터 정제, 전처리) 3. 두 집단간 동질성 검증(정규 분포 검정)
-> var.test(x, y, paired = TRUE)
4. 두 집단 평균 차이검정
-> t.test(x, y, paired = TRUE)
-> wilcox.test(x, y, paired = TRUE)
분석절차
< 가설 설정 >
연구가설(H1) : 교수법 프로그램을 적용하기 전 학생들의 학습력과 교수법 프로그램을 적용한 후 학생들의 학습력에 차이가 있다.
귀무가설(H0) : 교수법 프로그램을 적용하기 전 학생들의 학습력과 교수법 프로그램을 적용한 후 학생들의 학습력에 차이가 없다.
< 연구 환경 > A교육센터에서 교육생 100명을 대상으로 교수법 프로그램 적용 전에 실기시험을 실시한 후 1개월 동안 동일한 교육생에게 교수법 프로그램을 적용한 후 실기시험을 실시한 점수와 평균에 차이가 있는가 검정 한다.
1단계 파일 가져오기
data <- read.csv("C:/workspaces/R/data/paired_sample.csv", header = T)
head(data) # no before after
- 출력값 -
no before after
1 1 5.1 6.3
2 2 5.2 6.3
3 3 4.7 6.5
4 4 4.8 5.9
5 5 5.0 6.5
6 6 5.4 7.3
summary(data) # NA 4개
- 출력값 -
no before after
Min. : 1.00 Min. :3.000 Min. :5.000
1st Qu.: 25.75 1st Qu.:4.800 1st Qu.:5.800
Median : 50.50 Median :5.100 Median :6.200
Mean : 50.50 Mean :5.145 Mean :6.221
3rd Qu.: 75.25 3rd Qu.:5.600 3rd Qu.:6.500
Max. :100.00 Max. :7.000 Max. :8.000
NA's :4
View(data)
2단계 전처리( 대응 두 집단 subset 생성 )
result <- subset(data, !is.na(after), c(before, after)) # 96
head(result)
-출력값 -
before after
1 5.1 6.3
2 5.2 6.3
3 4.7 6.5
4 4.8 5.9
5 5.0 6.5
6 5.4 7.3
x <- result$before
y <- result$after
3단계 기술통계량
length(x) 출력값 : [1] 96 ()
length(y) 출력값 : [1] 96
- NA 제외한 평균 -
mean(x) 출력값 : [1] 5.16875
mean(y, na.rm=T) 출력값 : [1] 6.220833
- 동질성 검정
: 동질성 검정의 귀무가설 : 대응 두 집단 간 분포의 모양이 동질적이다.
- 동일 집단이기 때문에 동질성을 가질 것 같지만, 집단이 중요한 것이 아니라 데이터의 분포가 중요하고, 전과 후의 점수의 분포도의 특징은 비교해야합니다.
var.test(x, y, paired=T)
결과 p-value = 0.7361 > 0.05 : 동질성을 가지고 있다. -> t.test() - ( T검정 사용)
- 대응 두 집단 평균 차이 검정
① 단계1: 양측검정
t.test(x, y, paired = T)
결과 : p-value = 2.2e-16 < 0.05 : 귀무가설 기각
연구 가설 채택 : 교수법 프로그램을 적용하기 전 학생들의 학습력과 교수법 프로그램을 적용한 후 학생들의 학습력에 차이가 있다.
② 방향성을 갖는 단측가설 검정
- alternative = "less"
t.test(x, y, paired = T, alternative = "less", conf.level = 0.95)
p-value = 2.2e-16 < 0.05 / x를 기준으로 비교 : x가 y보다 작다.
- alternative = "greater"
t.test(x, y, paired = T, alternative = "greater", conf.level = 0.95)
p-value = 1 > 0.05 / x 를 기준으로 비교 : x가 y보다 크지 않다.
최종 결과 : 유의수준 0.05에서 귀무가설이 기각되 었다. 따라서 교수법 프로그램 적용 전과 적용 후의 두 집단간 학습력의 평균에 차이가 있다. 라고 말할 수 있다. 또한 단측검정을 실시한 결과 교수법 프로그램 적용 전 학습력이 교수법프로그램 적용 후 학습력 보다 크지 않은 것으로 나타났다. 즉 교수법 프로그램이 학습력에 효과가 있는 것으로 분석 된다.
- 단일 집단의 비율이 어떤 특정한 값과 같은지를 검정하는 방법 - 기술통계량으로 빈도 수에 대한 비율에 의미 - 단일 집단의 비율이 어떤 특정한 값과 같은지를 검정하는 방법(검정 방법 중에서 가장 간단)
방법: 1개 집단의 비율과 기존 집단과의 비율 차이 분석
작업절차
1. 실습 데이터 가져오기
2. 빈도수와 비율 계산
3. binom.test()이용
분석 절차
실습파일 가져오기 -> 데이터 전처리 -> 기술통계량(빈도분석) -> binom.test() -> 검정통계량 분석
<연구가설>
연구가설(H1) : 기존2014년도 고객 불만율과 2015년도 CS교육후 불만율에 차이가 있다. 귀무가설(H0) : 기존2014년도 고객 불만율과 2015년도 CS교육후 불만율에 차이가 없다
<연구환경> 2014년도 114 전화번호 안내 고객을 대상으로 불만을 갖는 고객은 20% 였다. 이를 개선하기 위해서 2015년도 CS교육을 실시한 후 150명 고객을 대상으로 조사한 결과 14명이 불만을 갖고 있었다. 기존20% 보다 불만율이 낮아졌다고 할 수 있는가?
x <- data$survey
x
summary(x) # 결측치 확인
- 출력값 -
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.0000 1.0000 1.0000 0.9067 1.0000 1.0000
length(x) 출력값 : [1] 150
table(x) # 빈도수(0:불만족(14), 1:만족(136))
x
- 출력값 -
0 1
14 136
3단계 기술통계량(빈도분석) - (패키지 이용 빈도수와 비율계산)
library(prettyR) # freq() 함수 사용
freq(x)
- 출력값 -
Frequencies for x
1 0 NA
136 14 0
% 90.7 9.3 0
%!NA 90.7 9.3
-- 이항분포 (만족율 기준) 비율검정 --
1) 양측 검정 (있다 or 없다)
binom.test(c(136, 14), p=0.8) # 기존 80% 만족율 기준 검증 실시
p-value = 0.0006735 < 0.05 보다 작다 -> 귀무가설 기각, 연구가설 채택(유의확률 값으로 결과 도출) 해설: 기존만족율(80%)과 차이가 있다. -> 연구가설채택 - 연구가설(H1) : 기존 2014년도 고객불만율과 2015년도 CS교육 후 불만율에 차이가 있다. 라는 결과를 도출합니다.
주의 사항) 차이가 없으면 문제가 없지만, 차이가 있게 되면 그 차이가 긍적적인지 부정적인지 판단할 수 없습니다.
2) 방향성을 갖는 단측 가설 검정 (방향성(긍정/부정)) - (유의확률 값이 유일수준 보다 작으면 채택)
p-value = 0.0003179 < 0.05 : 작으므로 채택(긍정적 차이를 얻어낸다)
- alternative = "less"
binom.test(c(136, 14), p=0.8, alternative = "less", conf.level = 0.95) # p-value = 0.9999
# less : 작다(방향성)
p-value = 0.9999 > 0.05 : 크므로 기각된다. - 사용하지 않는다.
결론 : 긍정적인 차이를 낸다.
-- 이항분포 (불만족 기준) 비율검정 --
1) 양측검정
binom.test(c(14, 136), p=0.2) # 기존 20% 불만족율 기준 검증 실시
p-value = 0.0006735 < 0.05 보다 작다 -> 귀무가설 기각, 연구가설 채택(유의확률 값으로 결과 도출) 해설: 기존만족율(80%)과 차이가 있다. -> 연구가설채택 - 연구가설(H1) : 기존 2014년도 고객불만율과 2015년도 CS교육 후 불만율에 차이가 있다. 라는 결과를 도출합니다.
< 양측검정은 불만족과 만족의 결과는 같습니다 >
2) 방향성을 갖는 단측 가설 검정 (유의확률 값이 유일수준 보다 작으면 채택)
- alternative = "greater"
binom.test(c(14, 136), p=0.2, alternative = "greater", conf.level = 0.95)
p-value = 0.9999 - 기각 ( 0.9999 > 0.05 )
- alternative = "less"
binom.test(c(14, 136), p=0.2, alternative = "less", conf.level = 0.95)
p-value = 0.0003179 - 채택 ( 0.0003179 < 0.05 )
결과 : 불만족의 부정적 차이 이므로 - 긍정적 차이를 나타낸다.
2 단일집단 평균검정(단일표본 T검정)
: 단일집단의 평균이 어떤 특정한 집단의 평균과 차이가 있는지를 검정하는 방법으로, 기술통계량으로 표본평균에 의미
방법: 두 집단 간 평균 차이에 관한 분석
작업절차
1. 실습 파일 가져오기 2. 두 집단 subset 작성(데이터정제,전처리) 3. 두 집단간 동질성 검증(정규 분포 검정)
-> var.test()
4. 두집단 평균 차이 검정
-> 정규분포를 따를 때 = t.test() or 정규분포를 따르지 않을 때 = wilcow.test()
분석절차
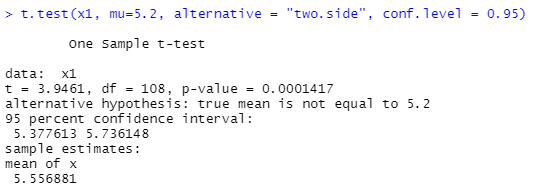
<가설설정> - 연구가설(H1) : 국내에서 생산된 노트북과 A회사에서 생산된 노트북의 평균 사용 시간에 차이가 있다. - 귀무가설(H0) : 국내에서 생산된 노트북과 A회사에서 생산된 노트북의 평균 사용 시간에 차이가 없다.
<연구환경> IT교육센터에서 PT를 이용한 프레젠테이션 교육방법과 실시간 코딩 교육 방법을 적용하여 1개월 동안 교육 받은 교육생 각150명을 대상으로 실기시험을 실시하였다. 두집단간 실기시험의 평균에 차이가 있는가 검정한다