
Practice makes perfect
[R] 비지도 학습의 방법 : 연관분석 (Association Analysis) 본문
연관분석 (Association Analysis)
: 연관분석은 군집분석에 의해서 그룹핑된 cluster를 대상으로 해당 그룹에 대한 특성을 분석하는 방법으로 장바구니 분석이라고 합니다. 즉, 유사한 개체들을 클러스터로 그룹화하여 각 집단의 특성 파악합니다. 예를 들어, 제가 마트에서 ’씨리얼’ 이라는 제품을 샀으면 그와 함께 먹을 우유도 같이 구매할 확률이 높을 것입니다. 이렇게 A라는 제품을 구매하였을 때, B라는 제품도 함께 구매하는 규칙의 패턴을 구하고자 하는 것이 연관규칙 분석의 목적입니다. 유튜브, 넷플릭스 등의 플랫폼들은 모두 이러한 알고리즘들을 기반으로 컨텐츠들을 추천해주고 있습니다.

연구 분석의 기본 개념
지지도(support)
: 전체 데이터에서 관광지 X, Y에 대한 방문을 모두 포함하는 비율 (2개 이상 컬럼)
- X -> Y 지지도 식 = X, Y 동시에 방문한 관광객 수 / 전체 관광객 수
= n(A, B) : 두 항목(X, Y)이 동시에 포함 수 / n : 전체 수
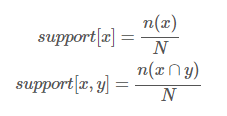
신뢰도(confidence)
: 관광지 X를 방문하였을 때, Y를 같이 방문할 조건부 확률
- X -> Y 신뢰도 식 = X,Y 동시에 방문한 관광객 수 / X 방문 관광객 수
= X와 Y를 포함한 수 / X를 포함한 수
- 값이 클수록 X를 방문하였을 때, Y를 같이 방문하는 비율이 높음 ( X를 방문하였을 때, Y를 방문할 비율 )

향상도(Life)
: 관광지 X를 방문하였을 때, Y를 같이 방문하는 경우와 관광지 X의 방문여부에 상관없이 Y를 방문한 경우의 비율 ( 관광지 간의 독립성과 상관성을 나타내는 척도 )
- 하위 항목들이 독립에서 얼마나 벗어나는지의 정도를 측정한 값
- 향상도 식 = X,Y 를 동시에 방문한 관광객 비율 / (X를 방문한 관광객 비율 * Y를 방문한 관광객 비율)
= 신뢰도 / Y가 포함될 거래율
- 향상도가 1에 가까우면 : 두 상품이 독립
- 1보다 작으면 : 두 상품이 음의 상관성(감기약과 위장약) - 공통점을 가지지만 다른 기능
- 1보다 크면 : 두 상품이 양의 상관성
- 분자와 분모가 동일한 경우 : Lift == 1, X와 Y가 독립(상관없음)
- 분자와 분모가 동일한 경우 : Lift != 1, X와 Y가 독립이 아닌 경우(상관있음)
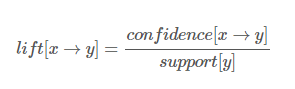
- 규칙 생성에서 support 값을 높게 설정할 수록 적은 수의 규칙만이 생성이 됩니다.(즉, 발생빈도가 높은 규칙들만 생성이 된다는 의미입니다.)
- confidence 수치가 높으면 관광지 X를 방문하면 Y를 방문할 확률이 높아지는 것과 같습니다.

= confidence 확률식
연관분석 추가 설명
- 데이터베이스에서 사건의 연관규칙을 찾는 무방향성 데이터마이닝 기법
- 마케팅에서 고객의 장바구니에 들어있는 품목 간의 관계 탐구
- 어떤 사건이 얼마나 자주 동시에 발생하는가를 표현하는 규칙 또는 조건
- y변수가 없는 비지도 학습에 의한 패턴 분석
무방향성(x -> y변수 없음)
- 사건과 사건 간 연관성(관계)를 찾는 방법 (예 : 기저귀와 맥주)
예) 장바구니 분석 : 장바구니 정보를 트랜잭션이라고 하며, 트랜잭션 내의 연관성을 살펴보는 분석기법
- 분석절차 : 거래내역 -> 품목 관찰 -> 규칙(Rule) 발견
- 관련분야 : 대형 마트, 백화점, 쇼핑몰 판매자 -> 고객 대상 상품추천
1. 고객들은 어떤 상품들을 동시에 구매하는가?
2. 라면을 구매한 고객은 주로 다른 어떤 상품을 구매하는가?
- 활용방안 : 위와 같은 질문에 대한 분석을 토대로 고객들에게
1) 상품정보 발송
2) 텔레마케팅를 통해서 패키지 상품 판매 기획,
3) 마트의 상품진열
1. 연관규칙 평가 척도
실습) 트랜잭션 객체를 대상으로 연관규칙 생성
① 연관분석을 위한 패키지 설치
install.packages("arules")
library(arules) #read.transactions()함수 제공
② 트랜잭션(transaction) 객체 생성
tran<- read.transactions("tran.txt", format="basket", sep=",") # 트랜잭션 객체 생성.
tran # 6개의 트랜잭션과 5개의 항목(상품) 생성
- 출력값 -
transactions in sparse format with
6 transactions (rows) and
5 items (columns)read.transactions : 트랜잭션의 형태로 변형 - 필수
③ 트랜잭션 데이터 보기
inspect(tran)
- 출력값 -
items
[1] {라면,맥주,우유}
[2] {고기,라면,우유}
[3] {고기,과일,라면}
[4] {고기,맥주,우유}
[5] {고기,라면,우유}
[6] {과일,우유} insect : 트랜잭션을 배열의 형태로 출력
④ 규칙(rule) 발견 - apriori
rule<- apriori(tran, parameter = list(supp=0.3, conf=0.1)) # 16 rule
inspect(rule) # 규칙 보기- supp, conf 가 높을수록 규칙성은 적어질 것이고, 낮을수록 규칙성은 많아질 것 입니다.

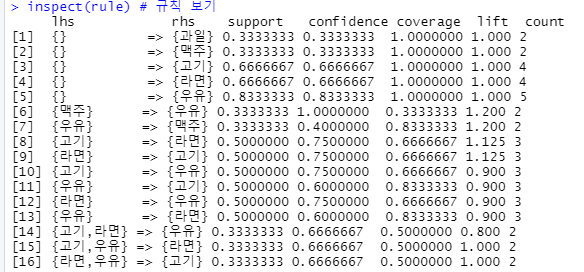
맥주 -> 우유 vs 우유 -> 맥주 : 지지도는 같지만 신뢰도는 조건부 확률이므로 다르게 나타납니다.
rule<- apriori(tran, parameter = list(supp=0.1, conf=0.1)) # 35 rule
inspect(rule) # 규칙 보기

2. 트랜잭션 객체 생성
실습) single 트랜잭션 객체 생성
stran <- read.transactions("demo_single",format="single",cols=c(1,2))
inspect(stran)
- 출력값 -
items transactionID
[1] {item1} trans1
[2] {item1,item2} trans2
single : 트랜잭션 구분자(Transaction ID)에 의해서 상품(item)이 대응된 경우
basket : 여러 개의 상품(item)으로 구성된 경우(Transaction ID 없이 여러 상품으로만 구성된 경우)
cols : single인 경우 읽을 컬럼 수 지정(basket은 생략)
- demo_single

실습) 중복 트랜잭션 제거
① 트랜잭션 데이터 가져오기
stran2<- read.transactions("single_format.csv", format="single", sep=",",
cols=c(1,2), rm.duplicates=T) sep : 각 상품(item)을 구분하는 구분자 지정.
rm.duplicates=T : 중복되는 트랜잭션은 제외하고 출력.
② 트랜잭션과 상품 수 확인
stran2
- 출력값 -
transactions in sparse format with
248 transactions (rows) and
68 items (columns)
③ 요약 통계 제공
summary(stran2) # 248개 트랜잭션에 대한 기술통계 제공
inspect(stran2) # 트랜잭션 확인 
- inspect(stran2)

실습) 규칙 발견(생성)
① 규칙 생성하기
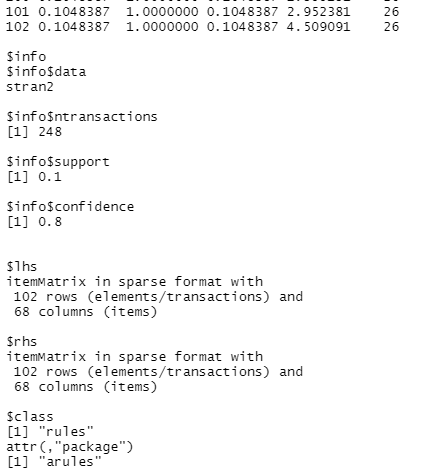
astran2 <- apriori(stran2) # supp=0.1, conf=0.8와 동일함
astran2 <- apriori(stran2, parameter = list(supp=0.1, conf=0.8)) # 위의 코드와 동일
astran2 출력값 : set of 102 rules
attributes(astran2)
.
.
.
② 상위 6개 향상도 내림차순으로 정렬하여 출력
inspect(head(sort(astran2, by="lift"))) # sort : 정렬 
실습) basket 트랜잭션 객체 생성
btran <- read.transactions("demo_basket",format="basket",sep=",")
inspect(btran) # 트랜잭션 데이터 보기
- 출력값 -
items
[1] {item1,item2}
[2] {item1}
[3] {item2,item3}트랜잭션 구분자(Transaction ID) 없이 상품으로만 구성된 데이터 셋을 대상으로 트랜잭션 객체를 생성할 경우 format="basket" 속성 지정
- demo_basket

3. 연관규칙 시각화
Adult 데이터 셋
Adult 데이터 셋
arules 패키지에서 제공되는 Adult는 성인을 대상으로 인구소득에 관한 설문 조사 데이터를 포함하고 있는 AdultUCI 데이터셋을 트랜잭션 객체로 변환하여 준비된 데이터 셋이다. AdultUCI 데이터 셋은 전체 48,842개의 관측치와 15개 변수로 구성된 데이터 프레임이다.
Adult 데이터셋은 종속 변수(Class)에 의해서 년간 개인 수입이 $5만 이상인지를 예측하는 데이터 셋으로 transactions 데이터로 읽어 온 경우 48,842개의 transaction 과 115 개의 item 으로 구성된다.
위의 데이터 셋을 활용하여 살펴보도록 하겠습니다.
실습) 다양한 신뢰도와 지지도 적용
지지도를 20%로 높인 경우 1,306개 규칙 발견
ar1<- apriori(Adult, parameter = list(supp=0.2))
지지도 20%, 신뢰도 95% 높인 경우 348개 규칙 발견
ar2<- apriori(Adult, parameter = list(supp=0.2, conf=0.95)) # 신뢰도 높임
지지도 30%, 신뢰도 95% 높인 경우 124개 규칙 발견
ar3<- apriori(Adult, parameter = list(supp=0.3, conf=0.95)) # 신뢰도 높임
지지도 35%, 신뢰도 95% 높인 경우 67 규칙 발견
ar4<- apriori(Adult, parameter = list(supp=0.35, conf=0.95)) # 신뢰도 높임
지지도 40%, 신뢰도 95% 높인 경우 36 규칙 발견
ar5<- apriori(Adult, parameter = list(supp=0.4, conf=0.95)) # 신뢰도 높임
실습) 규칙 결과보기
① 상위 6개 규칙 보기
inspect(head(ar5)) 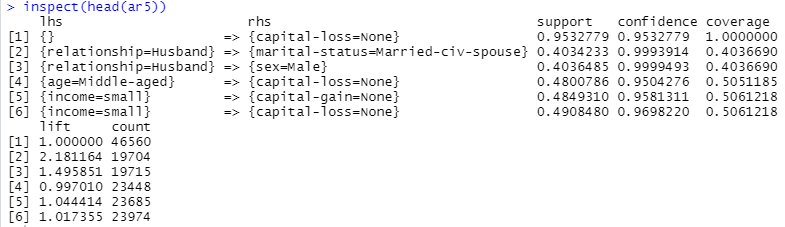
② confidence(신뢰도) 기준 내림차순 정렬 상위 6개 출력
inspect(head(sort(ar5, decreasing=T, by="confidence")))
③ lift(향상도) 기준 내림차순 정렬 상위 6개 출력
inspect(head(sort(ar5, by="lift"))) 
실습) 연관규칙 시각화
① 패키지 설치
install.packages("arulesViz")
library(arulesViz)
② 연관규칙 시각화
plot(ar3, method='graph', control=list(type='items'))
실습) Groceries 데이터 셋으로 연관분석하기
Groceries 데이터 셋
Groceries 데이터 셋
arules 패키지에서 제공되는 Groceries 데이터 셋은 1개월 동안 실제 로컬 식료품 매장에서 판매되는 트랜잭션 데이터를 포함하고 있다. 전체 9,835개의 트랜잭션(transaction)과 항목(item) 169 범주를 포함하고 있다.
위의 데이터를 활용하여 살펴보도록 하겠습니다.
① data.frame으로 형 변환
Groceries.df<- as(Groceries, "data.frame")
head(Groceries.df)
- 출력값 -
items
1 {citrus fruit,semi-finished bread,margarine,ready soups}
2 {tropical fruit,yogurt,coffee}
3 {whole milk}
4 {pip fruit,yogurt,cream cheese ,meat spreads}
5 {other vegetables,whole milk,condensed milk,long life bakery product}
6 {whole milk,butter,yogurt,rice,abrasive cleaner}
② 지지도 0.001, 신뢰도 0.8 적용 규칙 발견(410 rule(s))
rules <- apriori(Groceries, parameter=list(supp=0.001, conf=0.8))
inspect(rules) -> 410개
③ 규칙을 구성하는 왼쪽(LHS) -> 오른쪽(RHS)의 item 빈도수 보기
library(arulesViz)
plot(rules, method="grouped")

'빅데이터 > R' 카테고리의 다른 글
| [R] 시계열 분석(Timeseries Analysis) (7) | 2020.07.22 |
|---|---|
| [R] 비지도 학습의 방법 : 군집분석(Clustering Analysis) (0) | 2020.07.21 |
| [R] 지도학습의 방법 : 분류분석(Classification) (0) | 2020.07.20 |
| [R] 지도학습의 방법 : 회귀분석(Regression Analysis) (0) | 2020.07.17 |
| [R] 머신러닝(Machine Learning) (0) | 2020.07.17 |



